n<-rpois(1,50)
n[1] 37During our initial linear mixed effects models lecture I gave an example of mercury concentration in fish (walleye). We will revisit that example, and hopefully, the logic behind mixed effects models will be clearer!
While last time we looked at the example of Walleye in a Lake Michigan, this time we will look into a completely different example. Let’s assume we are still working with Walleye (or any other fish species of your choice, you can even rename it something else if you wish). We are still interested in mercury concentration based on size. However, we are looking at a completely different water body. This water body is only 20 acres!
Because, this water body is only 20 acres, we don’t think there is any spatial heterogeneity, so, we don’t have to worry too much about a spatial component. This makes our lives easier! We can simply set a net, catch the fish, and measure them without having to worry about mixed effects (for the time being).
Now, before we look at the data, we need to generate it. I don’t have a great dataset for this, so we will be simulating the data in this study and in this whole assignment!
This is OK. As we are simulating data, each run will be unique. This means each time you run a chunk of code it will give you a different result. Also, when you render your document, you will get a different result each time (each render runs each code chunk).
If you want to be able to replicate your example, you could set a seed set.seed(). I won’t be setting a seed for my example,.
If you are doing complex models, I always recommend you simulate some data (with known parameters) to test the models. This way, you know if the model is doing what you want it to do, and how close the estimates are to the real parameters! We will be doing that in this assignment.
The first step in our experiment is setting the net in the small-ish pond. The net should catch about 50 individuals. We will simulate our sampling using the following:
n<-rpois(1,50)
n[1] 37Where n is the number of fish we got. You can run that line multiple times and see that we get a different number each time!
Now, let’s check the size of our fish! Our net won’t catch any individuals under 20cm and fish size is uniformly distributed (in this example), with the largest fish being 60 cm.
Let’s check the size of teh fish we caught:
size<-runif(n,20,60)
print(size) [1] 36.59048 58.95365 32.45460 51.93880 33.89744 50.63884 44.93009 22.00319
[9] 24.62491 35.64622 48.84048 51.41785 23.36402 41.15016 26.39055 29.93507
[17] 49.98238 53.88218 41.98570 51.54603 34.47616 32.73130 43.81378 59.73174
[25] 40.41148 24.88586 31.29034 24.14301 52.24900 21.78679 35.74684 31.67983
[33] 34.74795 35.70133 23.43341 39.51598 56.83921Finally, let’s simulate the mercury concentration. It is dependent on the size of the fish. Let’s remember the linear model equation.
\[ y \sim \beta_0+\beta_{1}x_i + \epsilon \]
Where,
\[ \epsilon \sim Normal(0,\sigma^2) \]
Let’s simulate the data for the mercury concentration.
We’ll use 0.5 as our \(\beta_0\) and 0.018 as our \(\beta_1\) and 0.0064 as our variance (we will use standard deviation, so the square root).
Let’s explore the data we obtained:
Hg<-0.5 + 0.018*size + rnorm(n,0,0.08)
plot(Hg~size)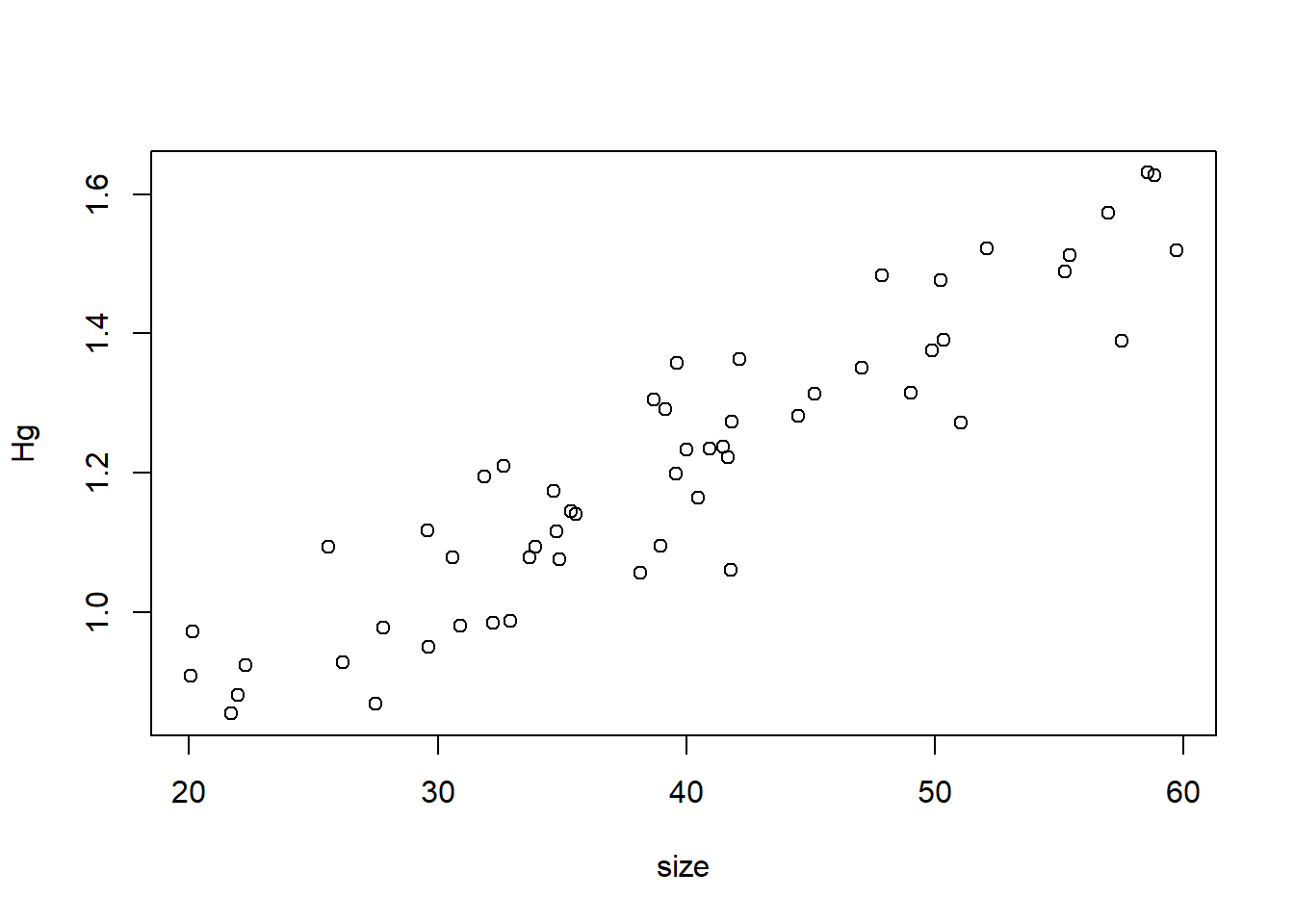
Looks good! Let’s make a data frame with all of our data:
df1<-data.frame(size=size,Hg=Hg)And let’s run a simple linear model:
model1<-lm(Hg~size,data=df1)
summary(model1)
Call:
lm(formula = Hg ~ size, data = df1)
Residuals:
Min 1Q Median 3Q Max
-0.21819 -0.04686 -0.00582 0.04781 0.20947
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.511308 0.052417 9.755 1.62e-11 ***
size 0.017182 0.001299 13.224 3.56e-15 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.08893 on 35 degrees of freedom
Multiple R-squared: 0.8332, Adjusted R-squared: 0.8285
F-statistic: 174.9 on 1 and 35 DF, p-value: 3.56e-15Look at the summary of your model, and answer: was the model good at estimating \(\beta_0\) (intercept), \(\beta_1\) (size) and the residual standard error?
Be aware that the results will change after you render, that is OK. You can leave your original answer here. Again, you can set the random seed, and have the results be reproducible if you want with set.seed() and putting a number.
Finally, we can plot it:
library(ggplot2)Warning: package 'ggplot2' was built under R version 4.3.3pred1<-predict(model1,df1,interval = "c")
dfplot<-cbind(df1,pred1)
ggplot(data=dfplot, aes(x=size,y=Hg,ymin=lwr,ymax=upr))+
geom_point()+
geom_line(aes(y=fit))+
geom_ribbon(alpha=0.2)+
theme_classic()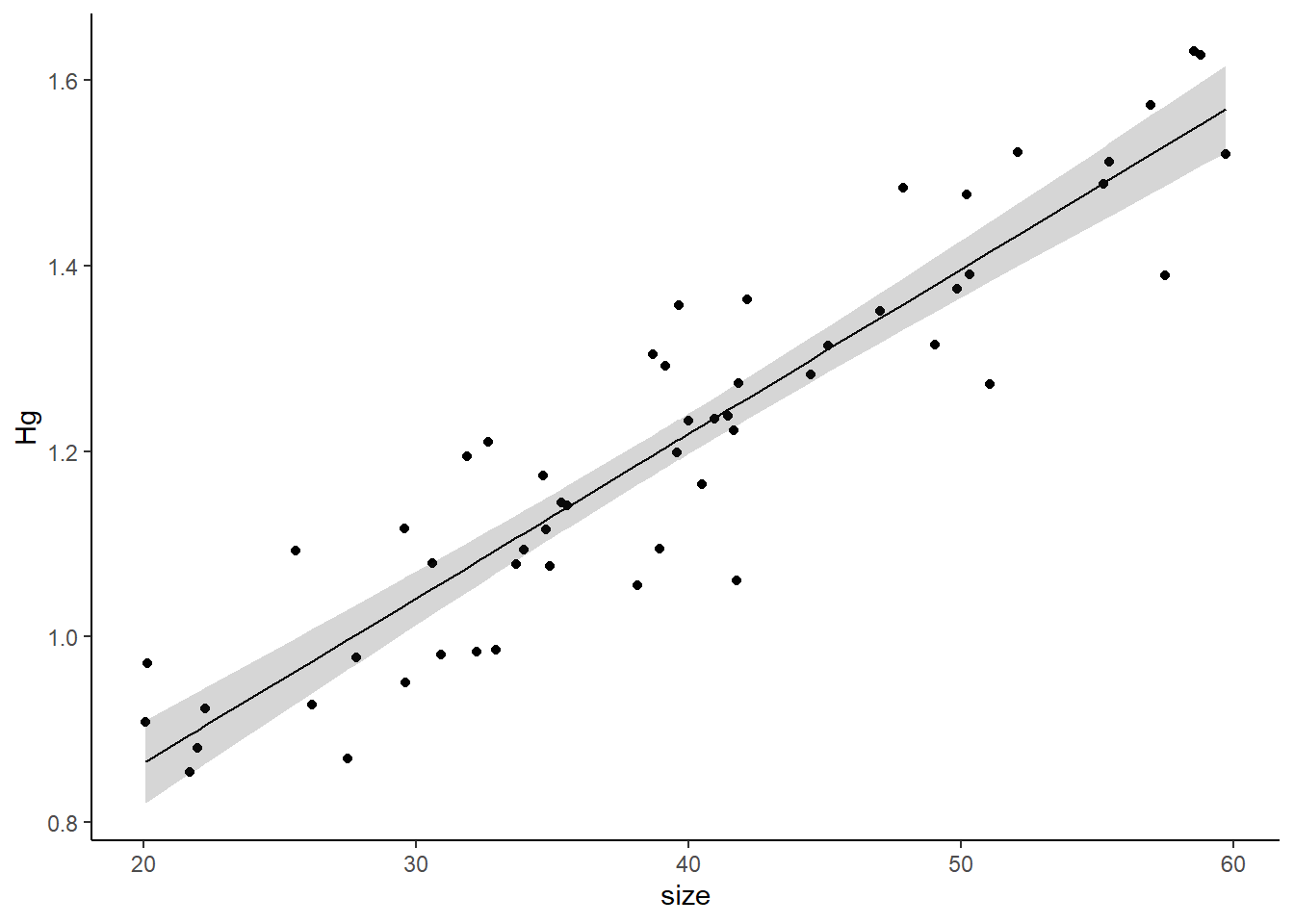
Let’s assume that we have three other ponds of the same size. So, we are going to do the same exact thing as we did in the first pond.
Let’s also assume that the relationship (the covariance, or the slope) of size and Hg concentration is the same in all three sites. So, now, the equation would be:
\[ y \sim \beta_0+\beta_{1}x_{1i} + \beta_{2}x_{2i} +\beta_{3}x_{3i} +\beta_{4}x_{4i} \epsilon \]
where,
\[ \epsilon \sim Normal(0,\sigma^2) \]
So, we have to come up with a value for \(\beta_2\), \(\beta_3\), and \(\beta_4\),
The way I am simulating this dataset is a bit unconventional. Usually you would come up with an equation for each population (or have a random function that selects the parameters). You would very rarely do it this way, but I am trying to follow the linear regression equations to simulate the data.
In this case, the values I am giving the betas are:
\(\beta_2\): 0.025
\(\beta_3\): 0.01
\(\beta_4\): 0.1
Remember, a \(\beta_j\) is the difference in the intercept between group j and group 1.
First, let’’s create a vector with the betas
beta<-c(0.025,0.01,0.1)
HgDat<-list(site1=df1)Then, let’s name our first pong region “A”:
df1$region<-"A"And create a list where we will store all of our results:
HgDat<-list(site1=df1)Finally, we do what we did with site 1:
for(i in 1:3){
n<-rpois(1,50)
size<-runif(n,20,60)
Hg<-0.5 + 0.018*size + rnorm(n,0,0.08)+beta[i]
Region<-rep(LETTERS[i+1],n)
HgDat[[i+1]]<-data.frame(size=size,Hg=Hg,region=Region)
}We stored all the data as a list, let’s now backtransform it to a data frame:
HgDat_df<-dplyr::bind_rows(HgDat)
HgDat_df$region<-as.factor(HgDat_df$region)
head(HgDat_df) size Hg region
1 36.59048 1.2049858 A
2 58.95365 1.5120609 A
3 32.45460 0.8507566 A
4 51.93880 1.4382598 A
5 33.89744 1.0676034 A
6 50.63884 1.3345326 ABefore we continue, I recommend you open the Hg_Dat dataframe and explore it.
Let’s now run the model:
model2<-lm(Hg~size+region,data=HgDat_df)
summary(model2)
Call:
lm(formula = Hg ~ size + region, data = HgDat_df)
Residuals:
Min 1Q Median 3Q Max
-0.213109 -0.049669 0.004391 0.051251 0.304392
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.4799912 0.0247916 19.361 < 2e-16 ***
size 0.0179905 0.0005386 33.403 < 2e-16 ***
regionB 0.0583006 0.0182725 3.191 0.00169 **
regionC 0.0323004 0.0187604 1.722 0.08695 .
regionD 0.1256087 0.0173215 7.252 1.41e-11 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.08145 on 169 degrees of freedom
Multiple R-squared: 0.8789, Adjusted R-squared: 0.876
F-statistic: 306.5 on 4 and 169 DF, p-value: < 2.2e-16and plot the data:
pred2<-predict(model2,HgDat_df,interval = "c")
dfplot<-cbind(HgDat_df,pred2)
ggplot(data=dfplot, aes(x=size,y=Hg,ymin=lwr,ymax=upr,col=region,shape=region,fill=region))+
geom_point()+
geom_line(aes(y=fit))+
geom_ribbon(alpha=0.2)+
theme_classic()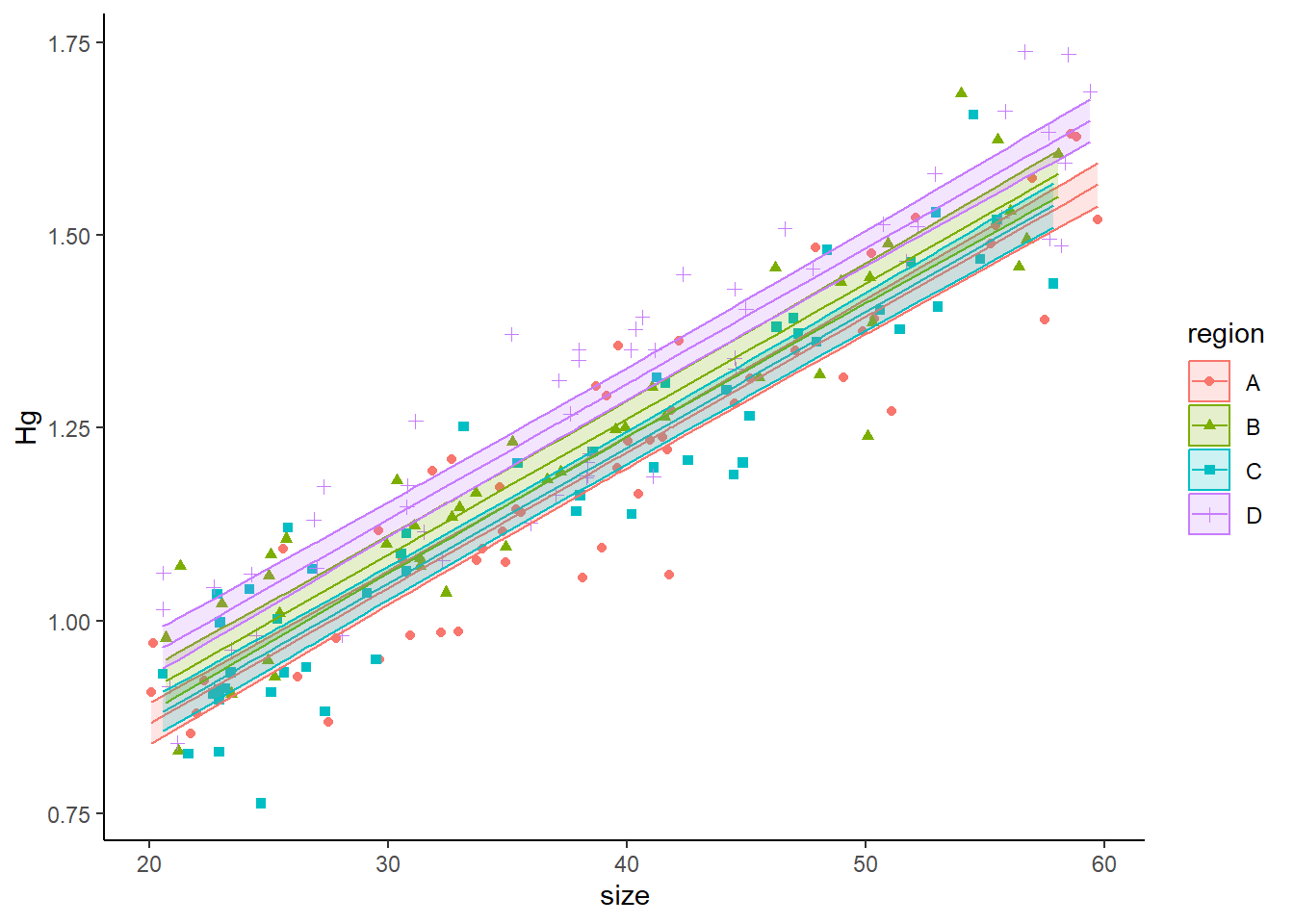
Look at the summary of your model, and answer: was the model good at estimating \(\beta_0\) (intercept), \(\beta_1\) (size), \(\beta_2\), \(\beta_3\), \(\beta_4\) and the residual standard error?
Run an Anova (in this case technically an Ancova, as there is covariance), and if there are region is significant, do a pairwise comparison.
We know (because we set the parameters) that every site is different. Is your pairwise comparison able to identify these differences among ALL groups? If it can’t, explain why you think it is failing at doing so.
Finally, run a different model with the same exact data where there is an interactive effect between site and region (AKA, slope is different). Compare the AIC values of both models? Did AIC correctly choose the additive model as the “best model”?
Let’s go back to our original Michigan Lake example
Here, we know there is a spatial effect of where we set our nets on the amount of mercury (still, the slope is the same). We will be placing four nets
And we don’t want to bias our estimate by choosing where to place the nets.
Also, we don’t care what site has a higher concentration of mercury. We care about the concentration lake-wide and about the variance introduced by the spatial heterogeneity.
Also, we don’t want to estimate a \(\beta\) for every net, we simply want to estimate the variance introduced by the spatial component (we don’t want to estimate 99 \(\beta's\) if we are setting 100 nets!). So, we are doing a mixed model (with a mixed intercept). As a reminder, this is the equation:
\[ Hg_{ij} \sim \underbrace{(\beta_0 +\underbrace{\gamma_j}_{\text{Random intercept}})}_{intercept} + \underbrace{\beta_1size_{i}}_{slope} +\underbrace{\epsilon}_\text{ind var} \]
where: \(\gamma_j \sim Normal(0,\sigma_\gamma)\) and \(\epsilon \sim Normal(0,\sigma)\).
Let’s say the variance introduced by the selection of site is 0.0625 (standard deviation of 0.25).
Then, we can create an object called \(\gamma\):
nsites<-4
gamma <- rnorm(n=nsites,mean=0,sd=0.25) Notice how I am not selecting the \(\beta's\) values? All I am providing is the standard deviation (think of this as teh variability introduced by where you place the nets. And using rnorm (random normal) I am obtaining 4 random values that affect the intercept. This is why this is a random component of the intercept.
Each time you run that line, you will get different values, because it is a random process (different than when we had 4 sites!)
HgDatmixed<-list()
for(i in 1:4){
n<-rpois(1,50)
size<-runif(n,20,60)
Hg<- (0.5+gamma[i]) + 0.018*size + rnorm(n,0,0.08)
Net<-rep(LETTERS[i],n)
HgDatmixed[[i]]<-data.frame(size=size,Hg=Hg,net=Net)
}
HgDatmixed<-dplyr::bind_rows(HgDatmixed)
HgDatmixed$net<-as.factor(HgDatmixed$net)Now, let’s run the mixed model:
library(glmmTMB)Warning: package 'glmmTMB' was built under R version 4.3.3m3<-glmmTMB(Hg~size +(1|net), data=HgDatmixed)
summary(m3) Family: gaussian ( identity )
Formula: Hg ~ size + (1 | net)
Data: HgDatmixed
AIC BIC logLik deviance df.resid
-423.7 -410.5 215.8 -431.7 194
Random effects:
Conditional model:
Groups Name Variance Std.Dev.
net (Intercept) 0.025235 0.15885
Residual 0.005939 0.07707
Number of obs: 198, groups: net, 4
Dispersion estimate for gaussian family (sigma^2): 0.00594
Conditional model:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 0.329132 0.081793 4.02 5.72e-05 ***
size 0.018178 0.000467 38.93 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Look at the summary of your model, and answer: was the model good at estimating \(\beta_0\) (intercept), \(\beta_1\) (size), and \(\gamma\)?
Now, let’s plot it. To plot it, we need two steps. First, we need to plot the data with the random intercepts:
preddata3 <- HgDatmixed
preddata3$predHg <- predict(m3, HgDatmixed)
plot2<- ggplot(data=HgDatmixed, aes(x=size, y=Hg, col=net, shape=net)) +
geom_point() +
geom_line(data=preddata3, aes(x=size, y=predHg, col=net))+
theme_classic()
plot2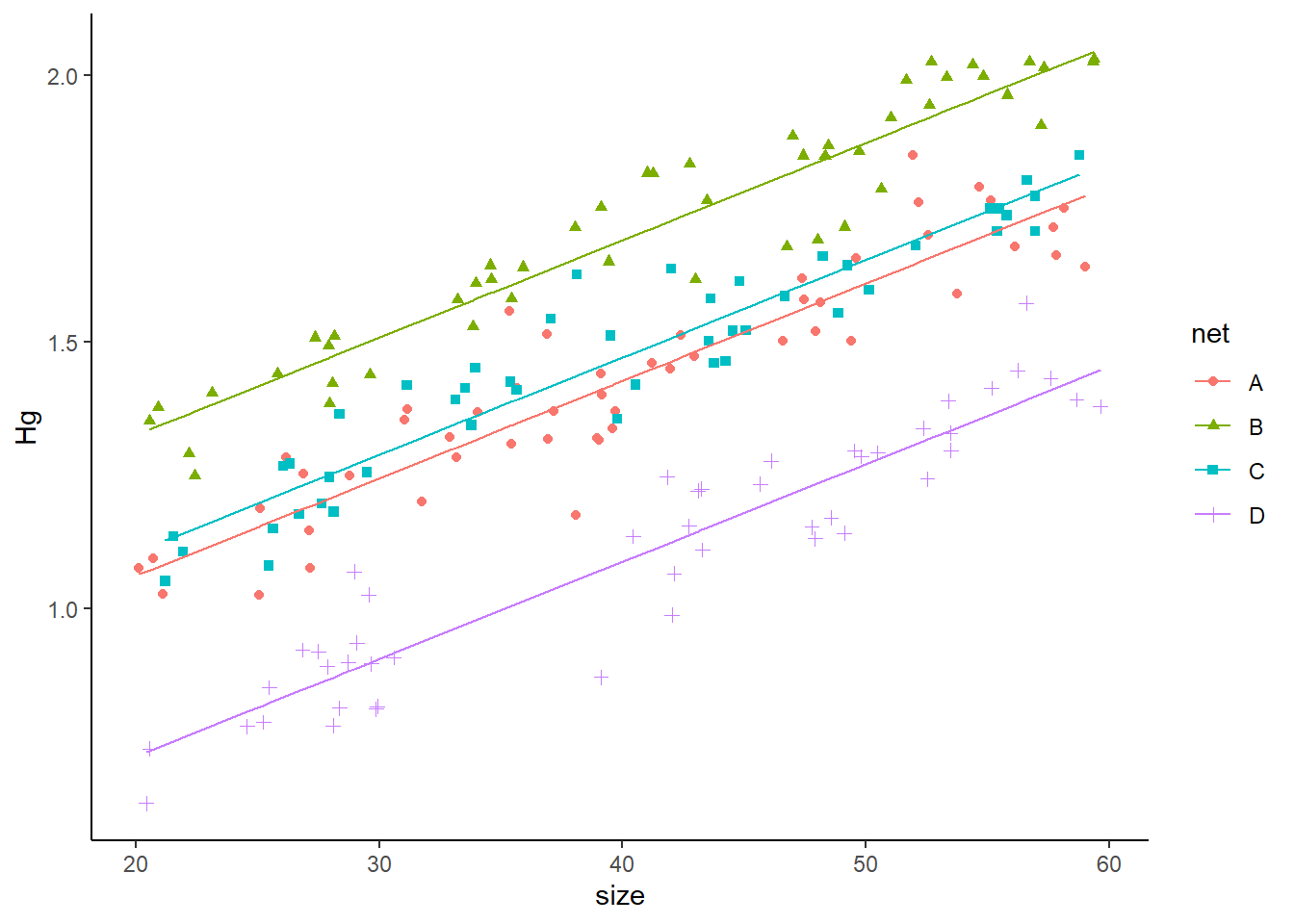
However, we also want to estimate the relationship between size and Hg for a “typical” individual. To do so, we set all random effects to 0 (we only estimate the fixed effects). We can do so with:
preddata3$predHg_population <- predict(m3, preddata3, re.form=~0)See how we added re.form=~0. That’s how we tell the function to predict the values given no random effects. We add this to our plot:
plot2<- ggplot(data=HgDatmixed, aes(x=size, y=Hg, col=net, shape=net)) +
geom_point() +
geom_line(data=preddata3, aes(x=size, y=predHg, col=net))+
geom_line(data=preddata3, aes(x=size, y=predHg_population),
col='black',linewidth=1.5) +
theme_classic()
plot2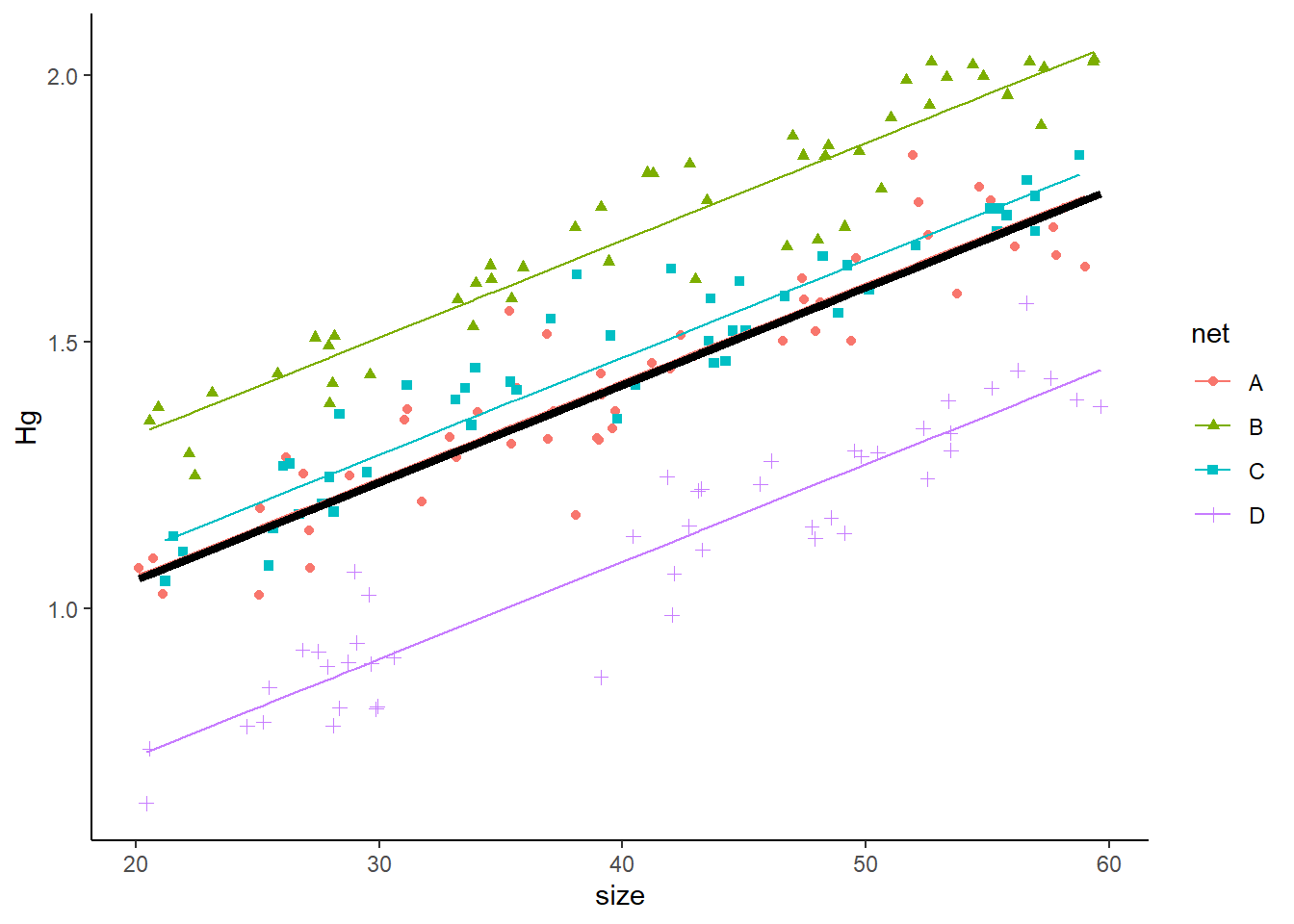
Run all the code in the “back to the Great Lakes” section again (actually do it 2 or 3 more times, no need to re-write it, just run it again). You should see how the random intercepts change each time you run them. Why do you think that happens?
Repeat the “back to the Great Lakes” section again, but this time you are setting 25 nets. Look the summary of that new model, and answer: was the model good at estimating \(\beta_0\) (intercept), \(\beta_1\) (size), and \(\gamma\)?
Finally, repeat that experiment, but this time there is no random intercept, but there is a random slope. Show the summary of the model
We can use cross-validation to test whether our model is good. To run it, we need to run the model as a linear model (i.e., just fixed effects):
library(caret)Warning: package 'caret' was built under R version 4.3.3Loading required package: latticectrl <- trainControl(method= 'cv', number= 10)
tr <- train(Hg~size +net, data=HgDatmixed, trControl= ctrl,method="lm")
trLinear Regression
198 samples
2 predictor
No pre-processing
Resampling: Cross-Validated (10 fold)
Summary of sample sizes: 178, 178, 178, 179, 178, 178, ...
Resampling results:
RMSE Rsquared MAE
0.07689254 0.9343731 0.06140988
Tuning parameter 'intercept' was held constant at a value of TRUEWe obtain a value of RMSE. The good thing is that this value actually has meaning and can be interpreted! It is the root mean square variation. It essentially measures the average differences between predicted and observed values. And it is in the same units (mg of Hg in this case). In this case the average difference was of 0.077. Whether that is good or bad depends on your system, but you should have enough knowledge of your system to reach a conclusion!
Notes:
\[ Hg_{ij} \sim \underbrace{\beta_0}_{intercept} + \underbrace{(\beta_1size_{i}+\underbrace{\psi}_{random \ slope}}_{slope} )+\underbrace{\epsilon}_\text{ind var} \]
where: \(\psi_j \sim Normal(0,\sigma_\psi)\) and \(\epsilon \sim Normal(0,\sigma)\).