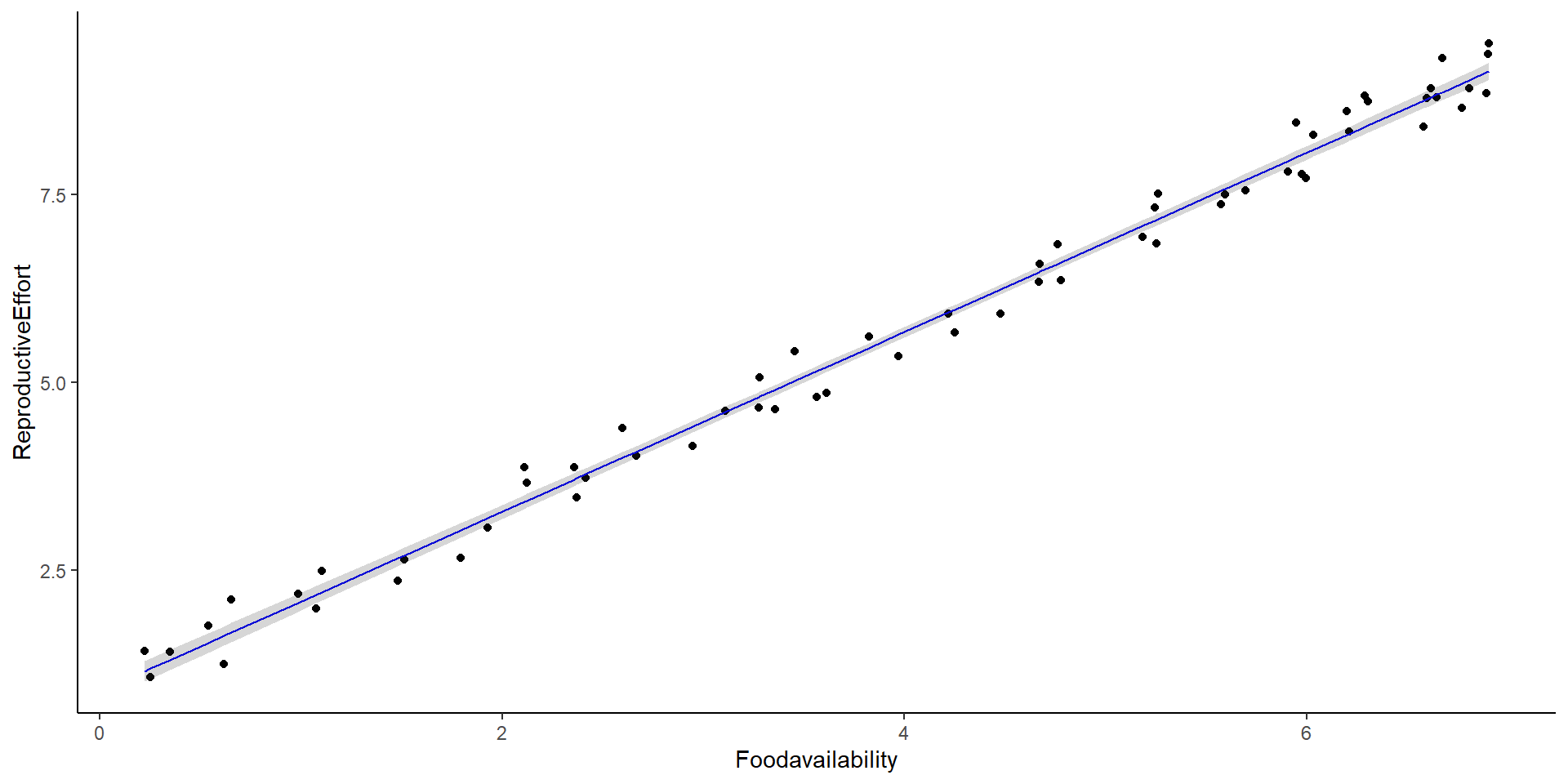
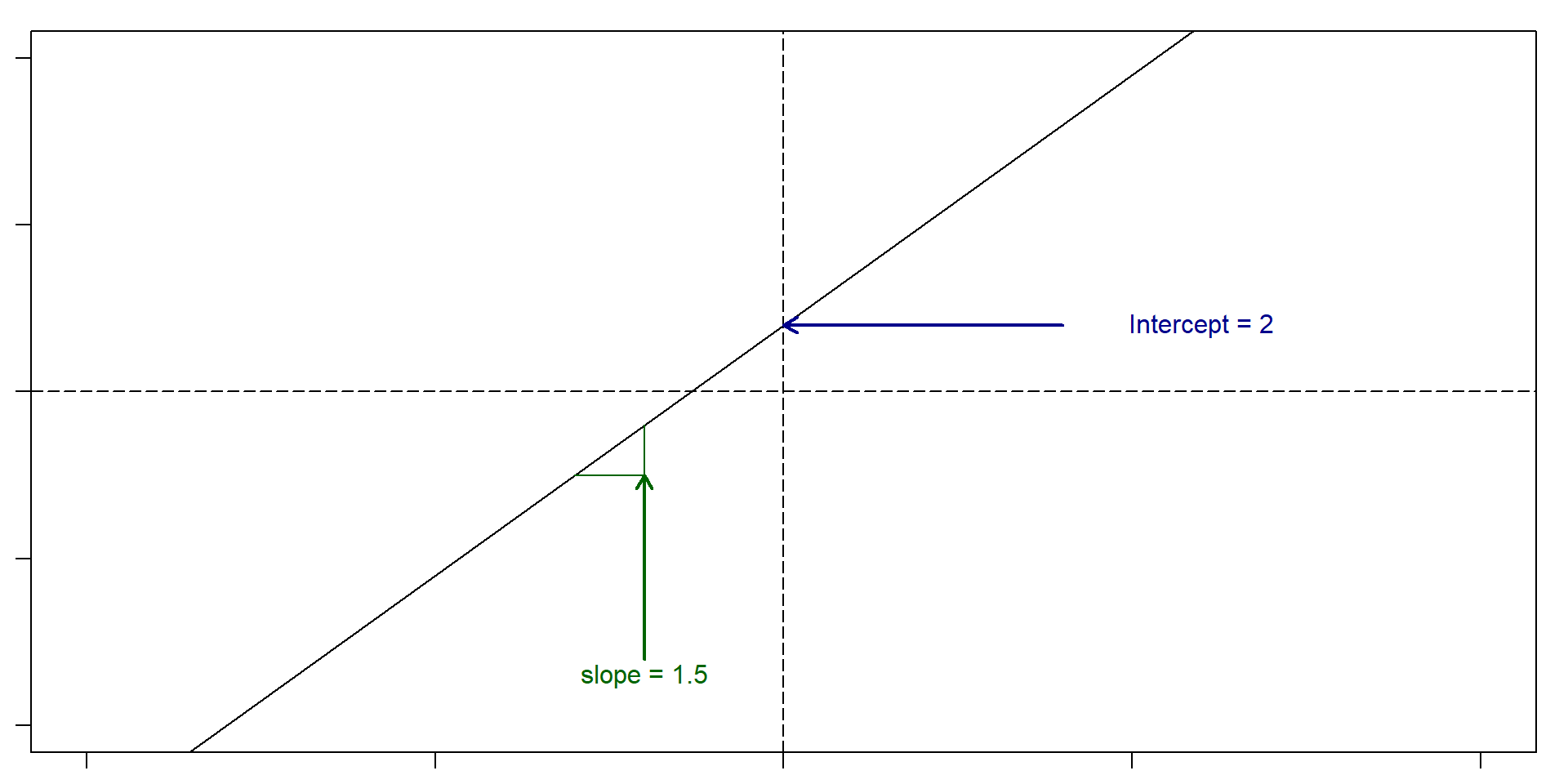
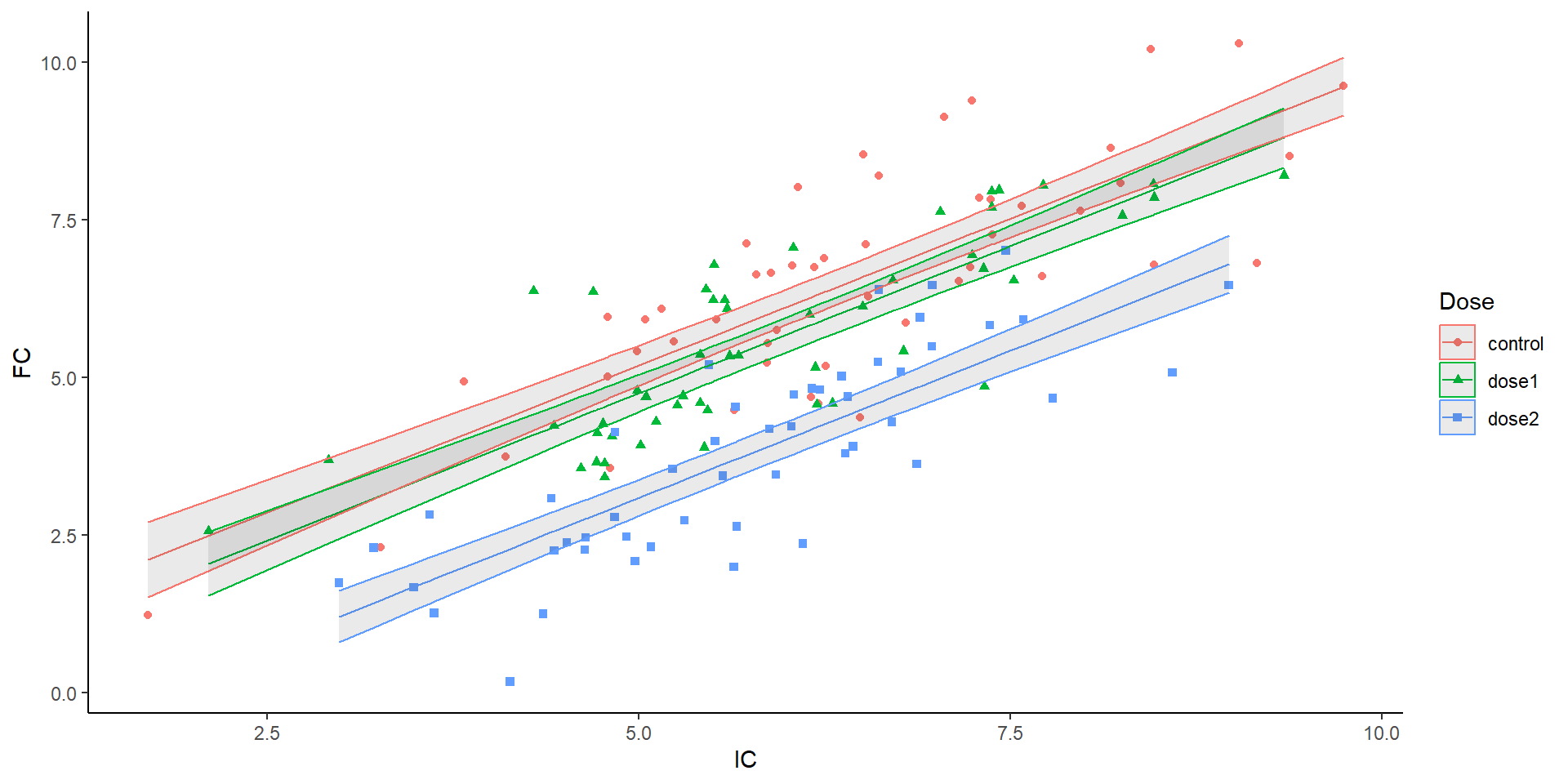
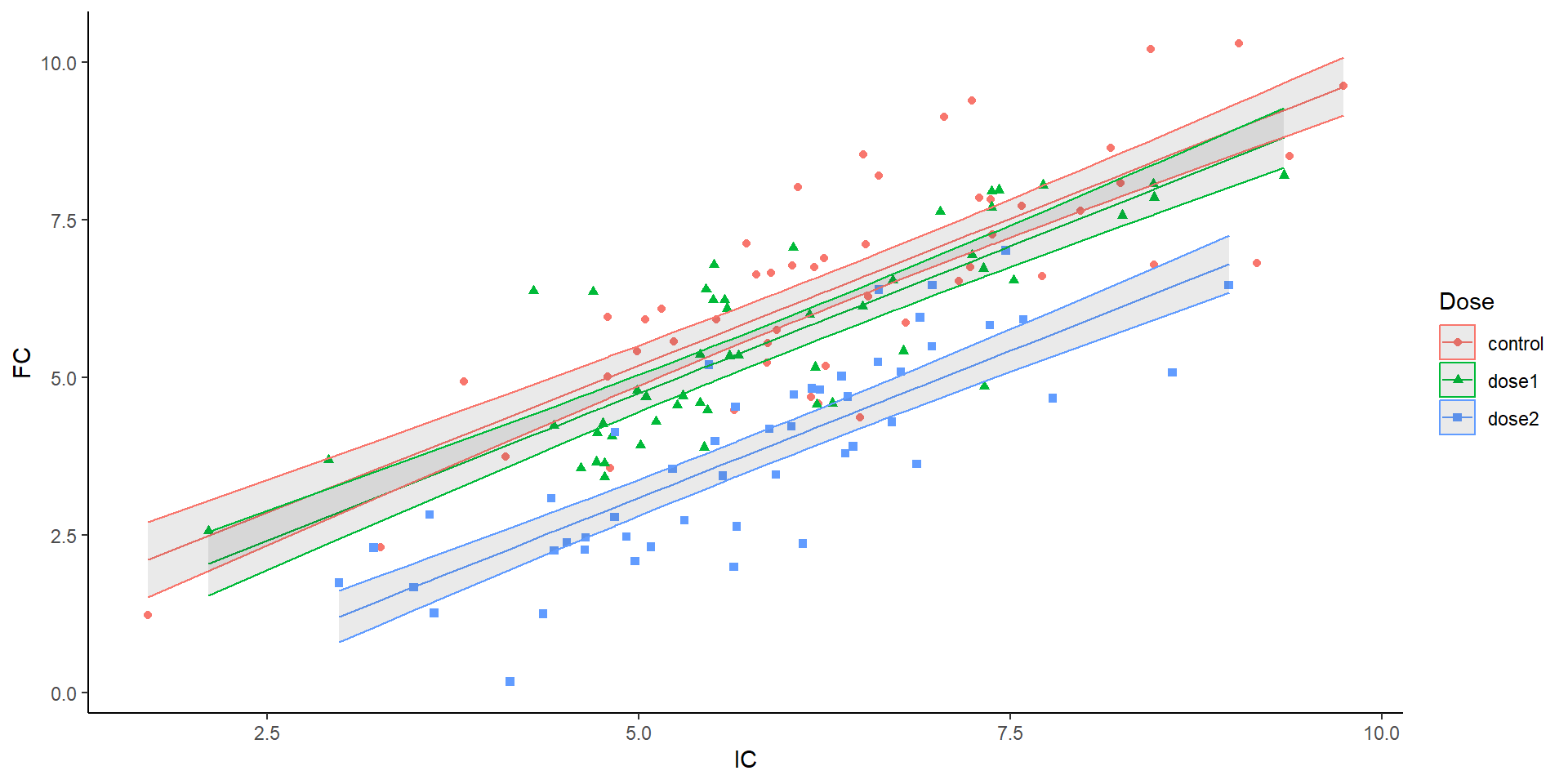
Call:
lm(formula = FC ~ IC + Dose, data = drugz)
Residuals:
Min 1Q Median 3Q Max
-2.2610 -0.6360 0.0000 0.6514 2.2876
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.51804 0.38892 1.332 0.1849
IC 0.93384 0.05647 16.537 <2e-16 ***
Dosedose1 -0.44007 0.20011 -2.199 0.0294 *
Dosedose2 -2.09915 0.20162 -10.412 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.9893 on 146 degrees of freedom
Multiple R-squared: 0.7636, Adjusted R-squared: 0.7588
F-statistic: 157.2 on 3 and 146 DF, p-value: < 2.2e-16
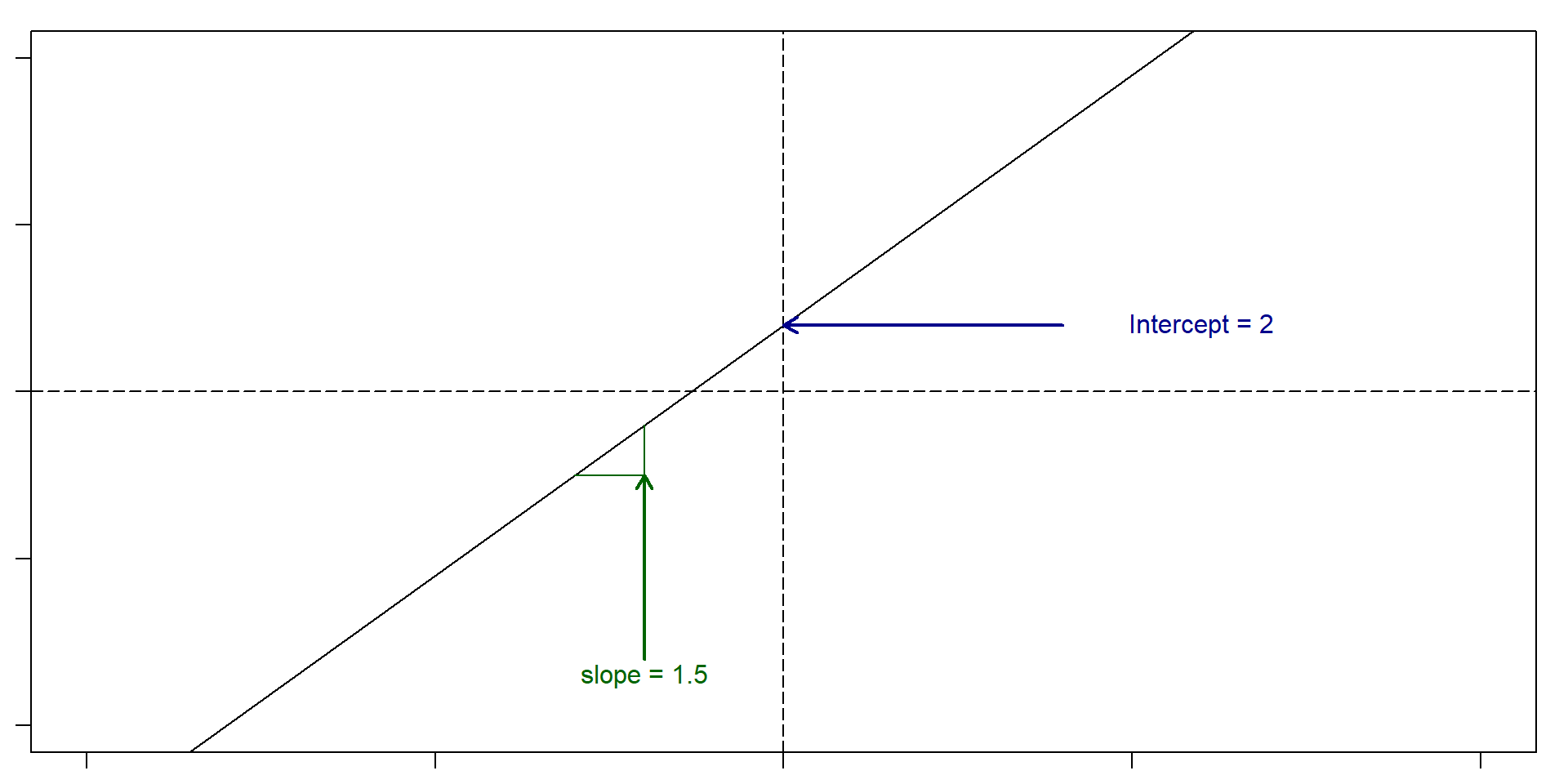
Measurement
Intercept
Slope
Control
0.51
0.93
Dose 1
0.51 - 0.44
0.93
Dose 2
0.51 -2.099
0.93
Statistical inference
anova
emmeans
contrast
Analysis of Variance Table
Response: FC
Df Sum Sq Mean Sq F value Pr(>F)
IC 1 342.36 342.36 349.825 < 2.2e-16 ***
Dose 2 119.30 59.65 60.949 < 2.2e-16 ***
Residuals 146 142.89 0.98
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
contrast estimate SE df t.ratio p.value
control - dose1 0.44 0.200 146 2.199 0.0747
control - dose2 2.10 0.202 146 10.412 <.0001
dose1 - dose2 1.66 0.198 146 8.377 <.0001
P value adjustment: tukey method for comparing a family of 3 estimates
statistical inference
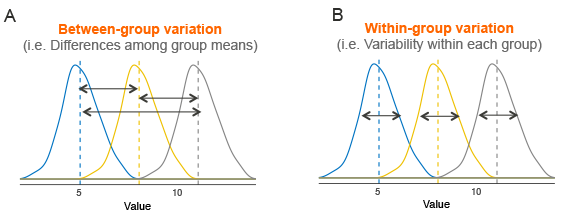
anova compares variance. Is the variance between groups higher than within groups?
Interactive
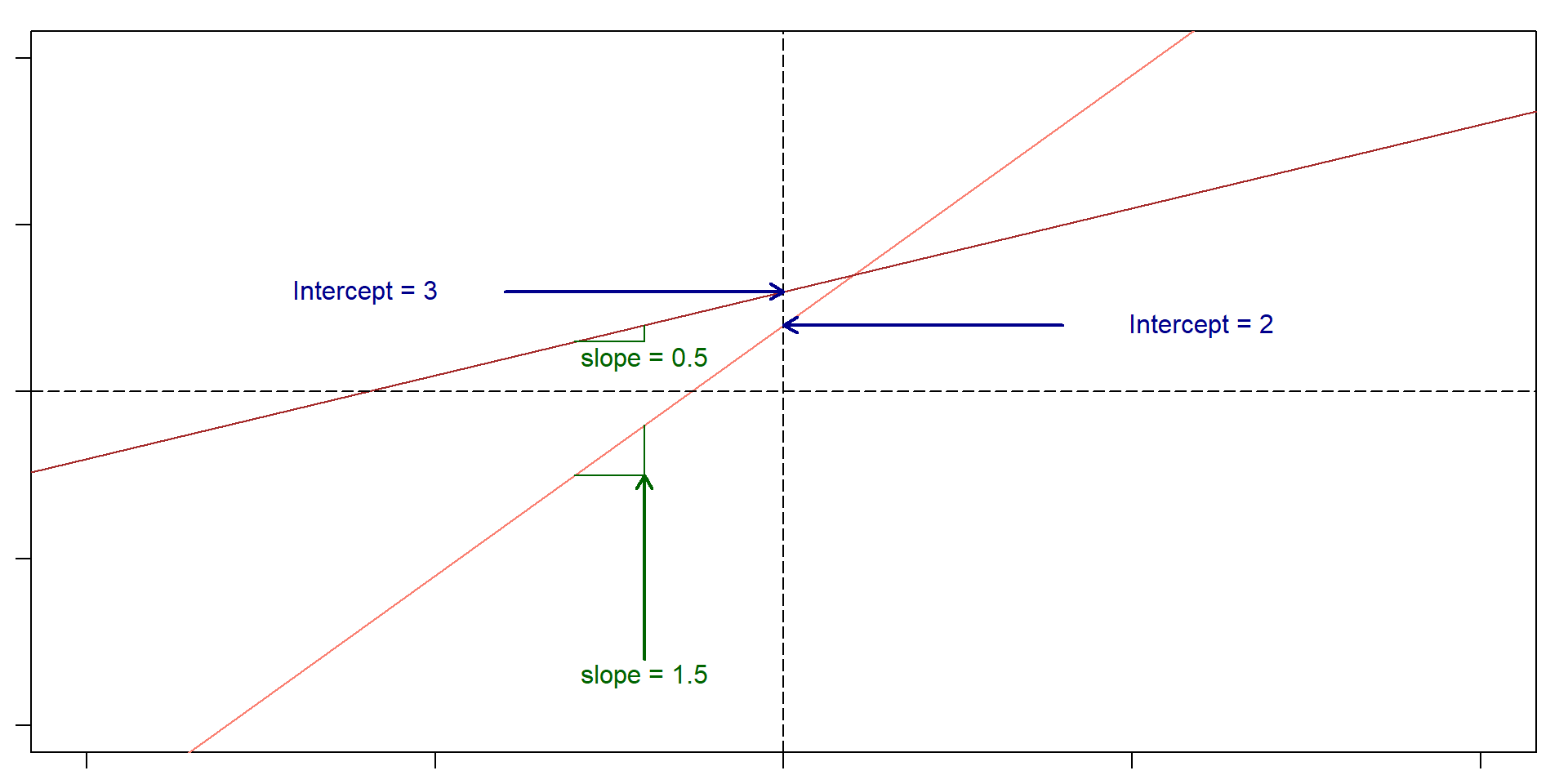
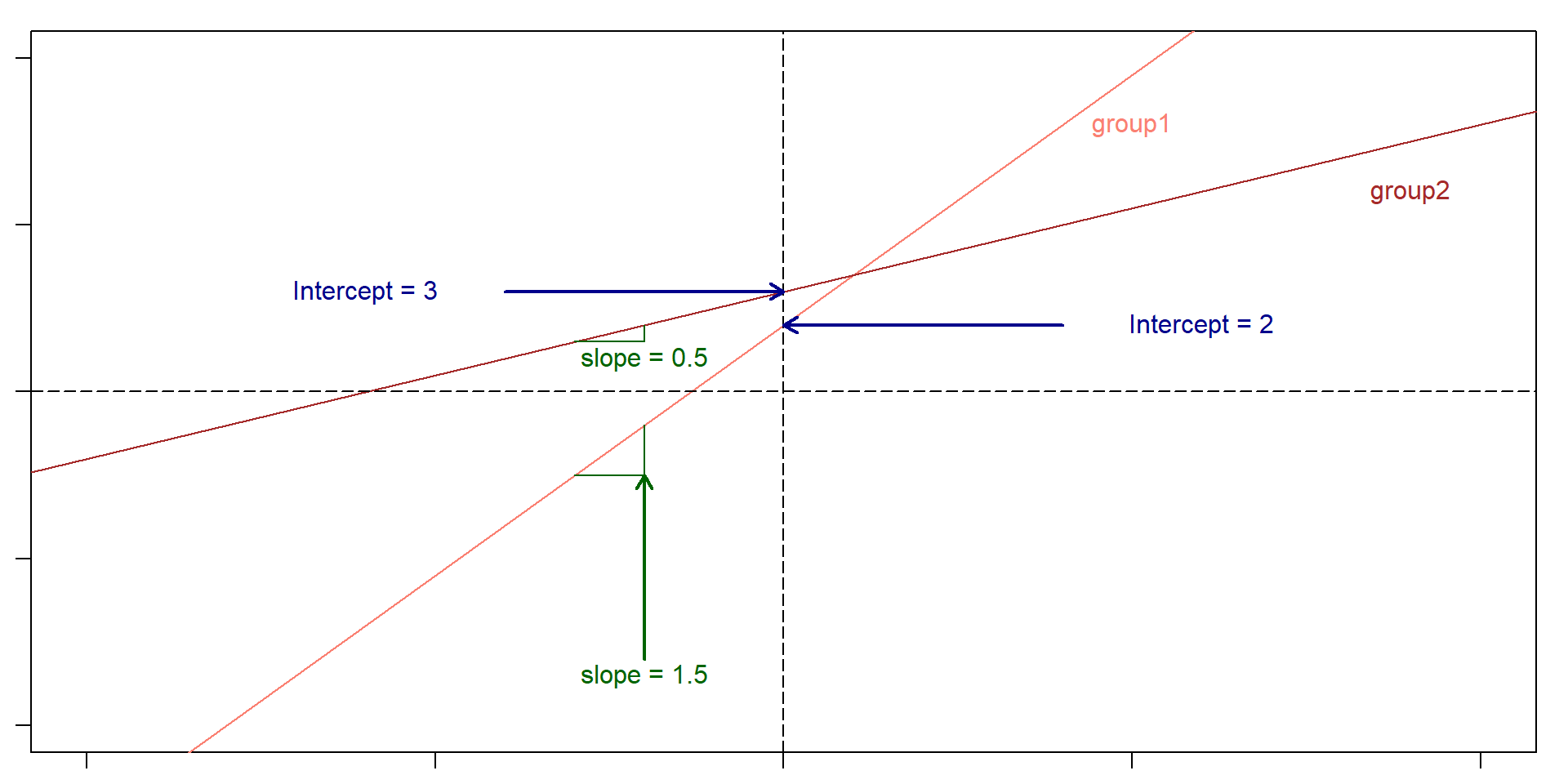
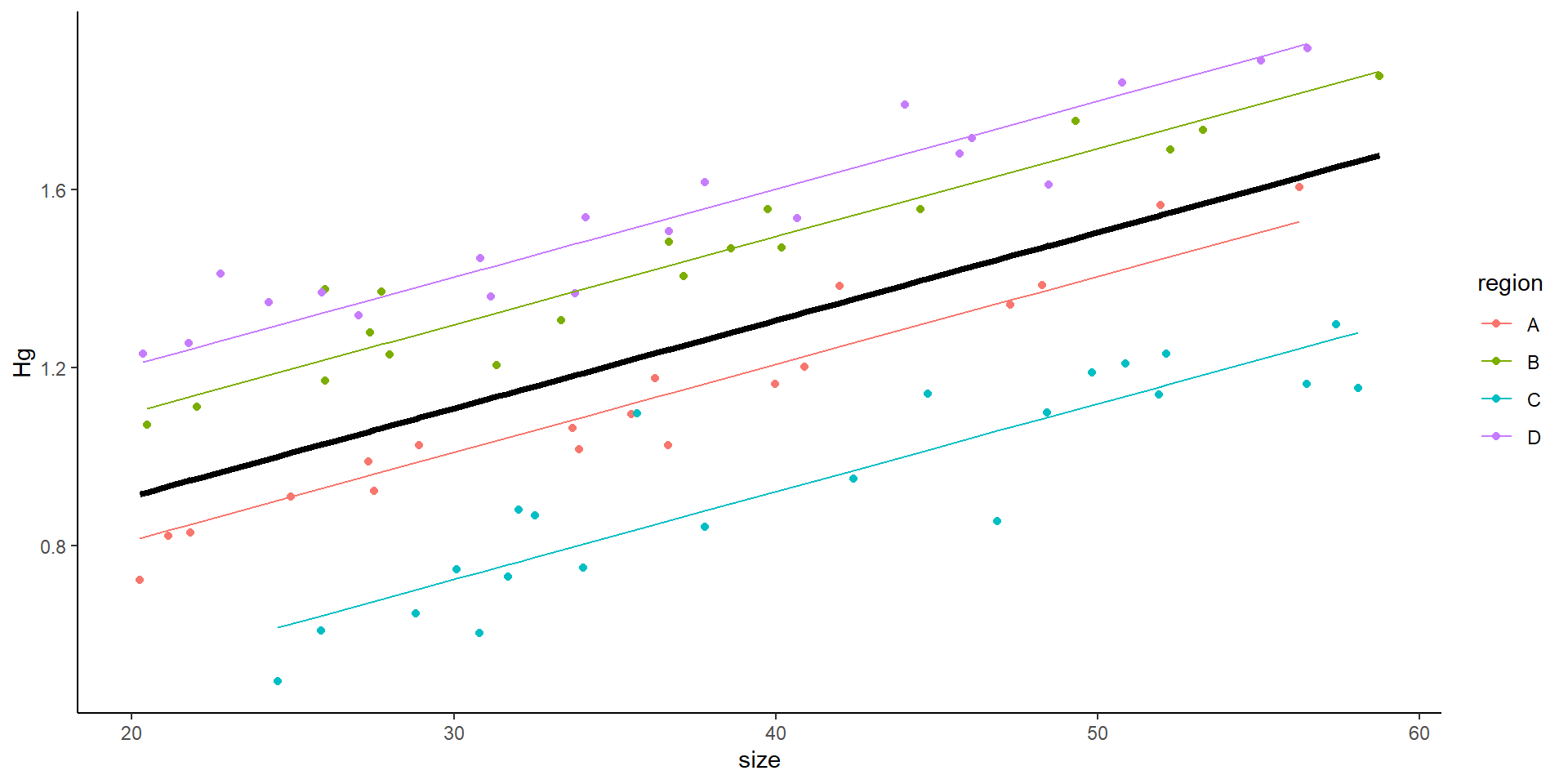
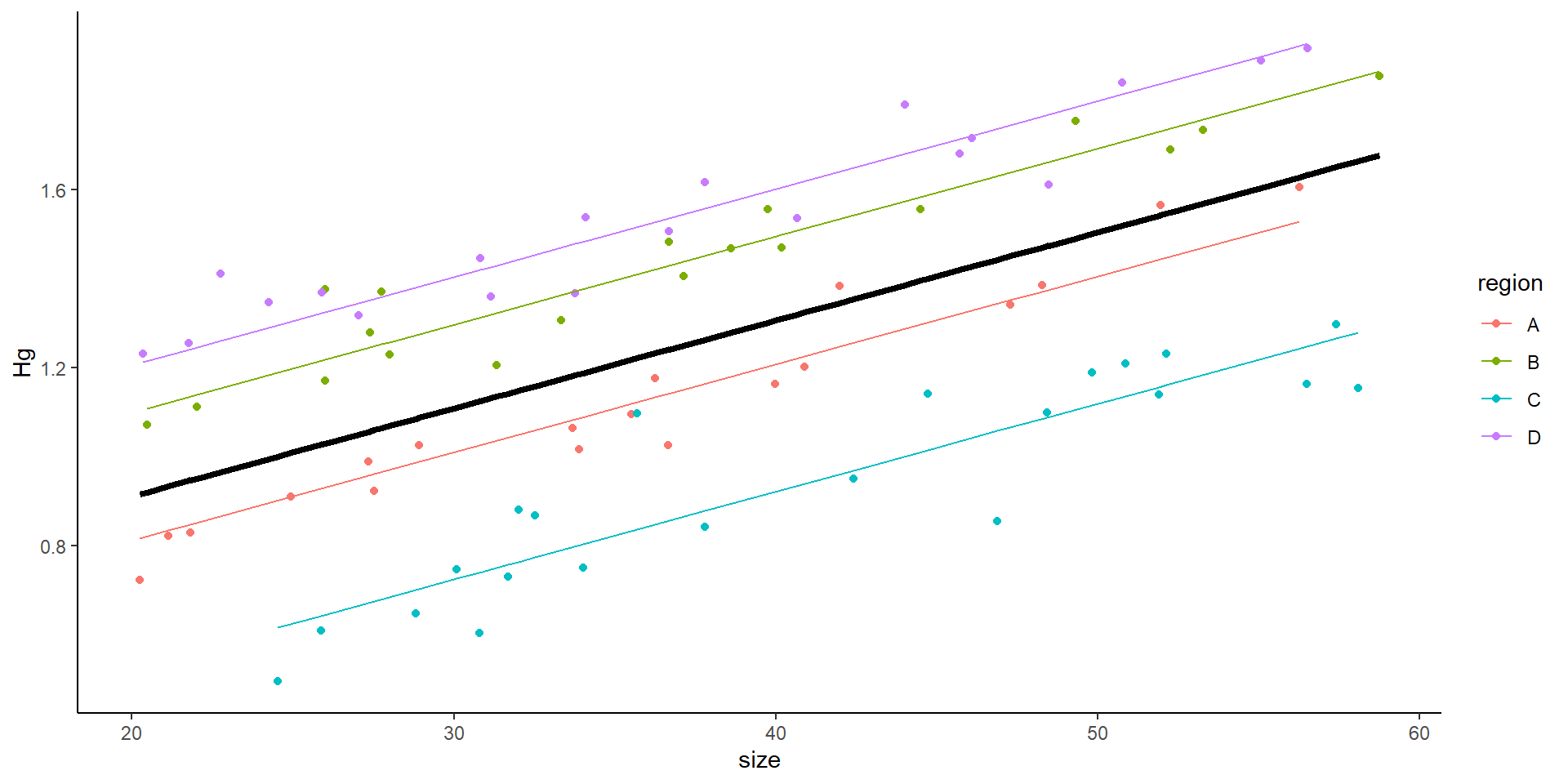
Each line has its own slope and its own intercept
Interactive
Call:
lm(formula = FC ~ IC * Dose, data = drugz)
Residuals:
Min 1Q Median 3Q Max
-2.3167 -0.6262 -0.0031 0.6443 2.1836
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.38733 0.59401 0.652 0.5154
IC 0.95418 0.08981 10.624 <2e-16 ***
Dosedose1 0.07353 0.85237 0.086 0.9314
Dosedose2 -2.21858 0.86308 -2.571 0.0112 *
IC:Dosedose1 -0.08529 0.13509 -0.631 0.5288
IC:Dosedose2 0.02324 0.13917 0.167 0.8676
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.9939 on 144 degrees of freedom
Multiple R-squared: 0.7647, Adjusted R-squared: 0.7565
F-statistic: 93.59 on 5 and 144 DF, p-value: < 2.2e-16
\[
\begin{align}
\beta_0 & = 0.38 \ \text{intercept for control} \\
\beta_1 & = 0.954 \ \text{slope for control} \\
\beta_2 & = -0.073 \ \text{Difference in intercept between control and dose 1} \\
\beta_3 & = -2.24 \ \text{Difference in intercept between control and dose 2} \\
\beta_4 & = -0.085 \ \text{Difference in slope between control and dose 1} \\
\beta_5 & = 0.023 \ \text{Difference in slope between control and dose 2} \\
\end{align}
\]
Site
Value of \(x_2\)
Value of \(x_3\)
Value of \(x_4\)
Value of \(x_5\)
Control
0
0
0
0
Dose 1
1
0
1
0
Dose 2
0
1
0
1
Doing inference of interactions
Analysis of Variance Table
Response: FC
Df Sum Sq Mean Sq F value Pr(>F)
IC 1 342.36 342.36 346.5514 <2e-16 ***
Dose 2 119.30 59.65 60.3790 <2e-16 ***
IC:Dose 2 0.63 0.31 0.3168 0.729
Residuals 144 142.26 0.99
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
NOTE: Results may be misleading due to involvement in interactions
contrast estimate SE df t.ratio p.value
control - dose1 0.44 0.202 144 2.173 0.0794
control - dose2 2.08 0.204 144 10.175 <.0001
dose1 - dose2 1.64 0.201 144 8.136 <.0001
P value adjustment: tukey method for comparing a family of 3 estimates
Interactions
Finding values (predictions)
Assignment question 1 📝
Look at the summary. And before continuing make sure you understand it. If you don’t, now is the time to raise your hand.
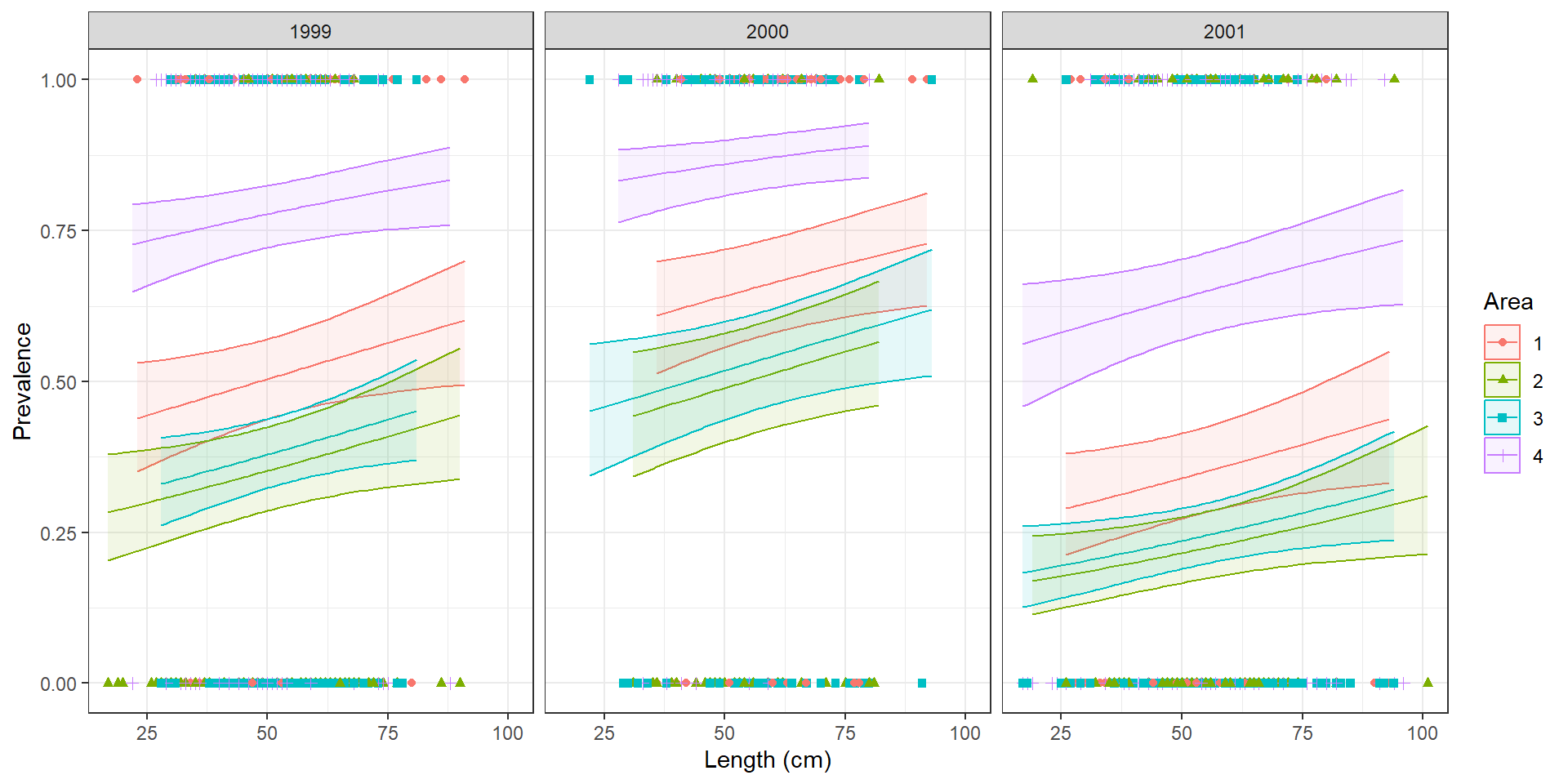
You need to calculate the expected probability (we’ll call this \(\pi\)) of an individual being infected for each of the following two cases:
An individual of length 50 from Area 1, in 1999
An individual of length 50 from Area 3, in 2001
GLM
Model
Call:
glm(formula = Prevalence ~ Length + Year + Area, family = binomial(link = "logit"),
data = cod)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.465947 0.269333 -1.730 0.083629 .
Length 0.009654 0.004468 2.161 0.030705 *
Year2000 0.566536 0.169715 3.338 0.000843 ***
Year2001 -0.680315 0.140175 -4.853 1.21e-06 ***
Area2 -0.626192 0.186617 -3.355 0.000792 ***
Area3 -0.510470 0.163396 -3.124 0.001783 **
Area4 1.233878 0.184652 6.682 2.35e-11 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1727.8 on 1247 degrees of freedom
Residual deviance: 1537.6 on 1241 degrees of freedom
(6 observations deleted due to missingness)
AIC: 1551.6
Number of Fisher Scoring iterations: 4
These are all from a linear model. Need to transform them to get the real value in probabilistic scale
Additive! One slope
How to estimate the values?
Call:
glm(formula = Prevalence ~ Length + Year + Area, family = binomial(link = "logit"),
data = cod)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.465947 0.269333 -1.730 0.083629 .
Length 0.009654 0.004468 2.161 0.030705 *
Year2000 0.566536 0.169715 3.338 0.000843 ***
Year2001 -0.680315 0.140175 -4.853 1.21e-06 ***
Area2 -0.626192 0.186617 -3.355 0.000792 ***
Area3 -0.510470 0.163396 -3.124 0.001783 **
Area4 1.233878 0.184652 6.682 2.35e-11 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1727.8 on 1247 degrees of freedom
Residual deviance: 1537.6 on 1241 degrees of freedom
(6 observations deleted due to missingness)
AIC: 1551.6
Number of Fisher Scoring iterations: 4
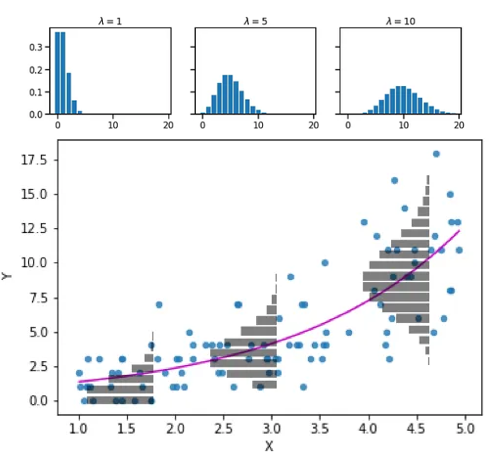
While we usually think Poisson, it has an important assumption: \(Var(y_i) = \lambda\_i\)
How to check for overdispersion?
Package: performance
performance::check_overdispersion(model)
What to do when there is overdispersion?
I have never encountered non-overdispersed count data!
So, what to do?
Add more covariates
Make a mixed effects model
Zero inflated models!
performance::check_zeroinflation(fit.pr)
What to do when there is overdispersion?
If we suspect zero inflation, we have several options for zero inflated models
Negative binomial regression
Hurdle models
Zero-inflated mixture model (mixed-effects)
GLM’s other assumptions
Data is independently distributed
Error is independent
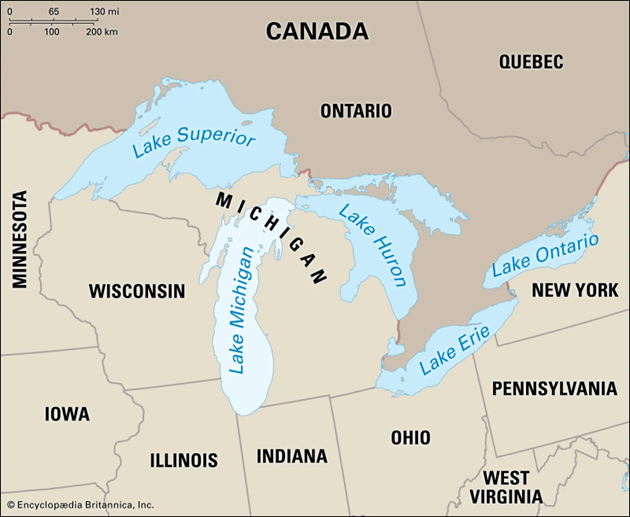
Question 1
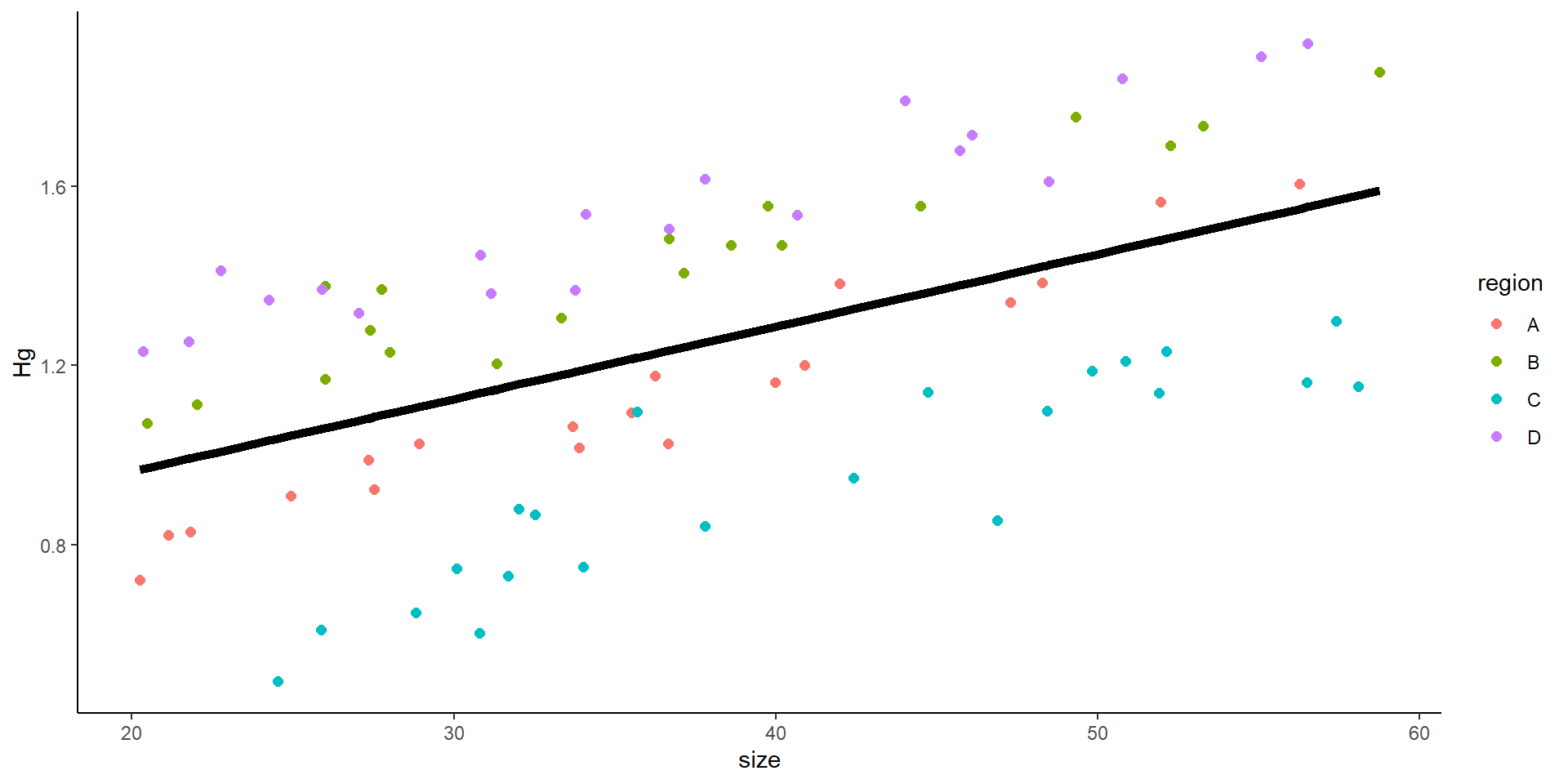
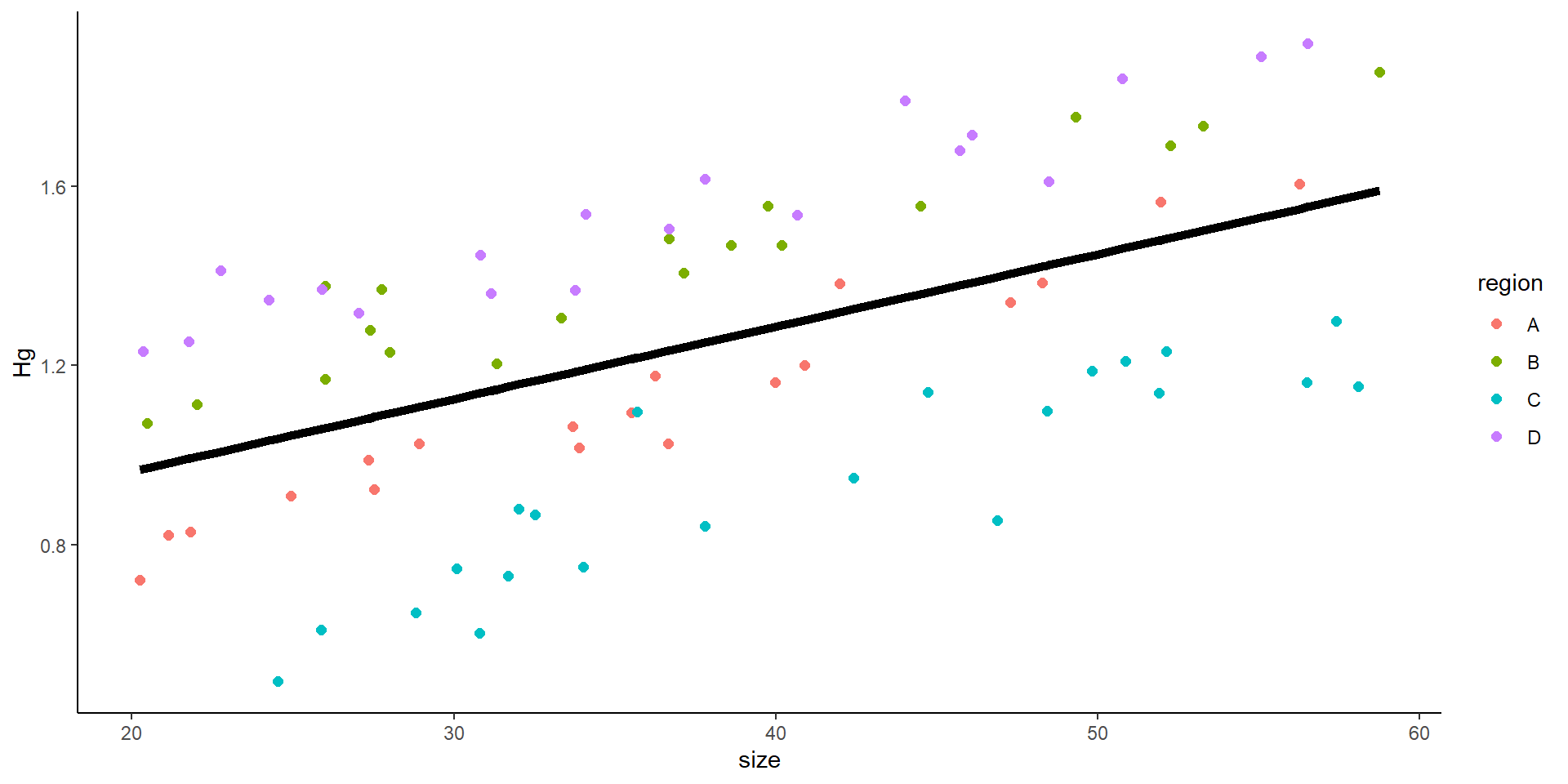
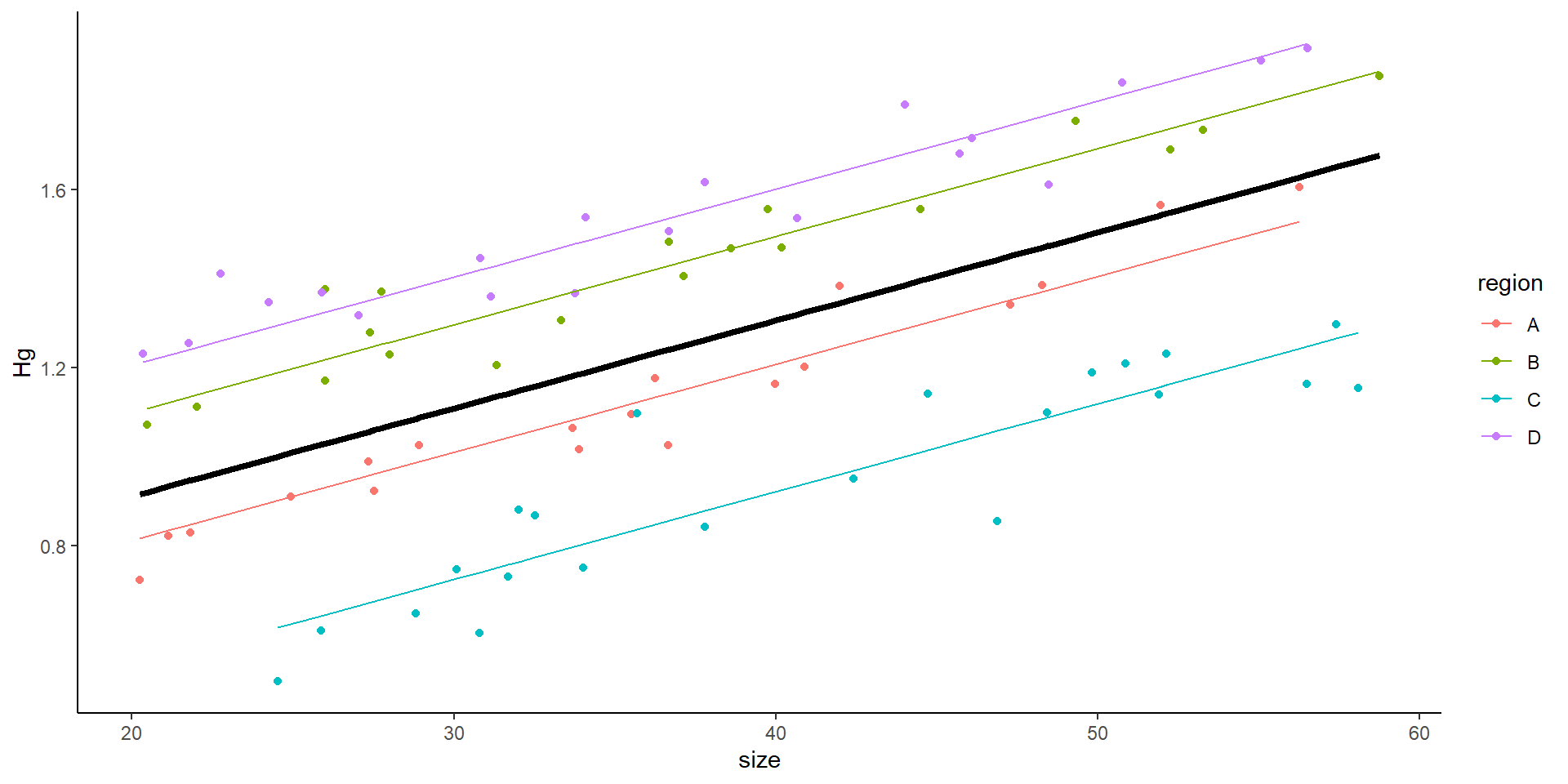
Interested in the concentration of mercury in Lake Michigan
We use code to randomly select 4 sites
At each site we set up a net
Return later and test Hg concentration of each fish
Question 1:
What is the experimental unit?
What is the response variable?
Where is sampling coming from or being introduced?
What do we care about?
Question 2:
We are testing infection prevalence in turkeys 🦃
We trap multiple individuals from a flock, and test them all 🦃
We do this for multiple flocks
What is introducing variance?
Question 3
We are testing the effects of a new drug on mice
You have 100 🐁. And three groups: control, dose 1 and dose 2
You measure their heartbeat pre-trial, 5 weeks post trial, and 10 weeks post trial
Do we care about individual 🐭 or the general effect of the drug?
Question 4
Government is studying how quickly people return to work after receiving unemployment benefits at a national level based on their educational level
Each observation is an individual
Response variables are duartion of benefit, and explanatory variables are education, and industry
You randomly select 25 regional offices to obtain the data
We want to know national levels, but do regional differences matter?
Research Questions
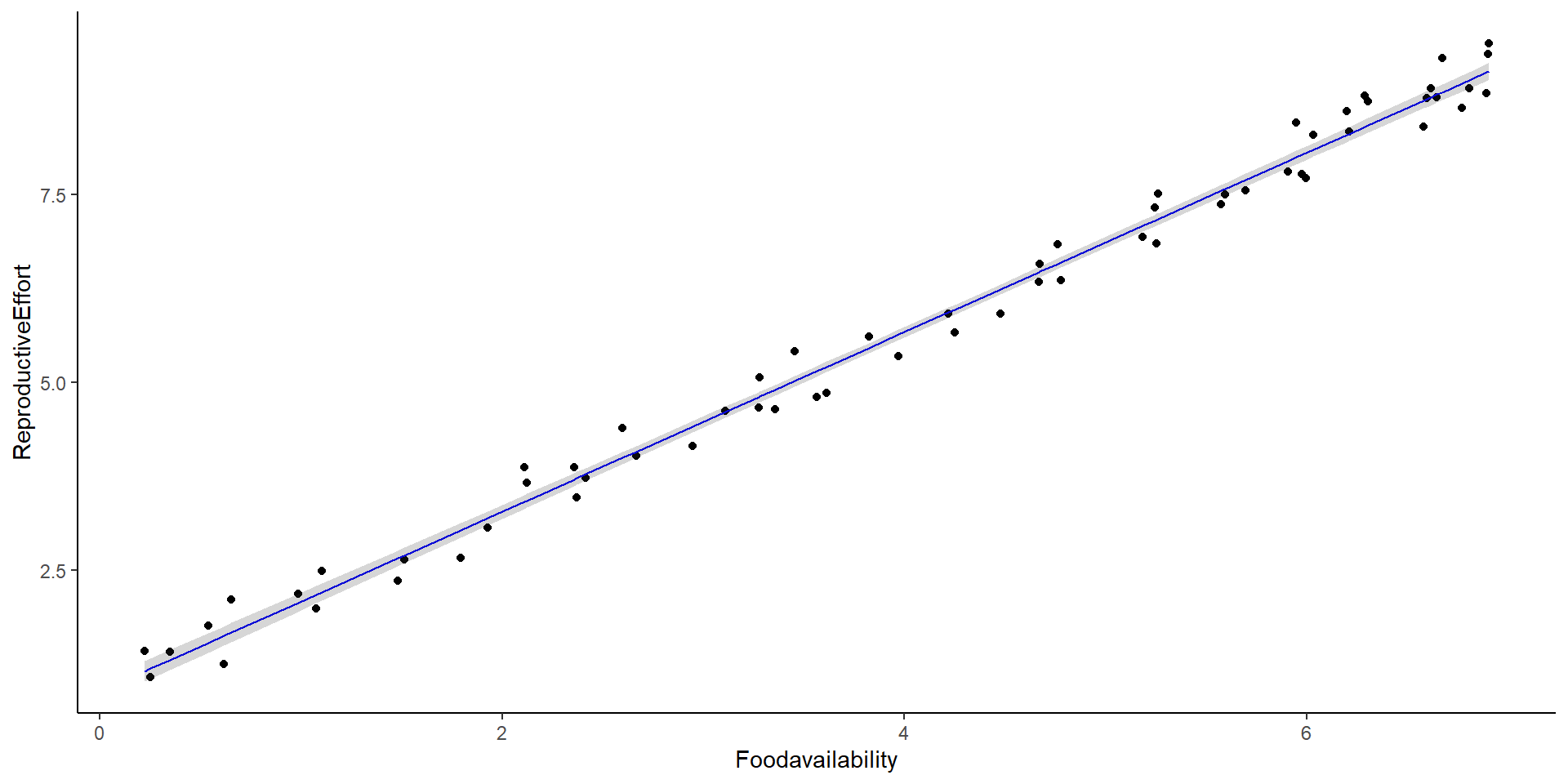
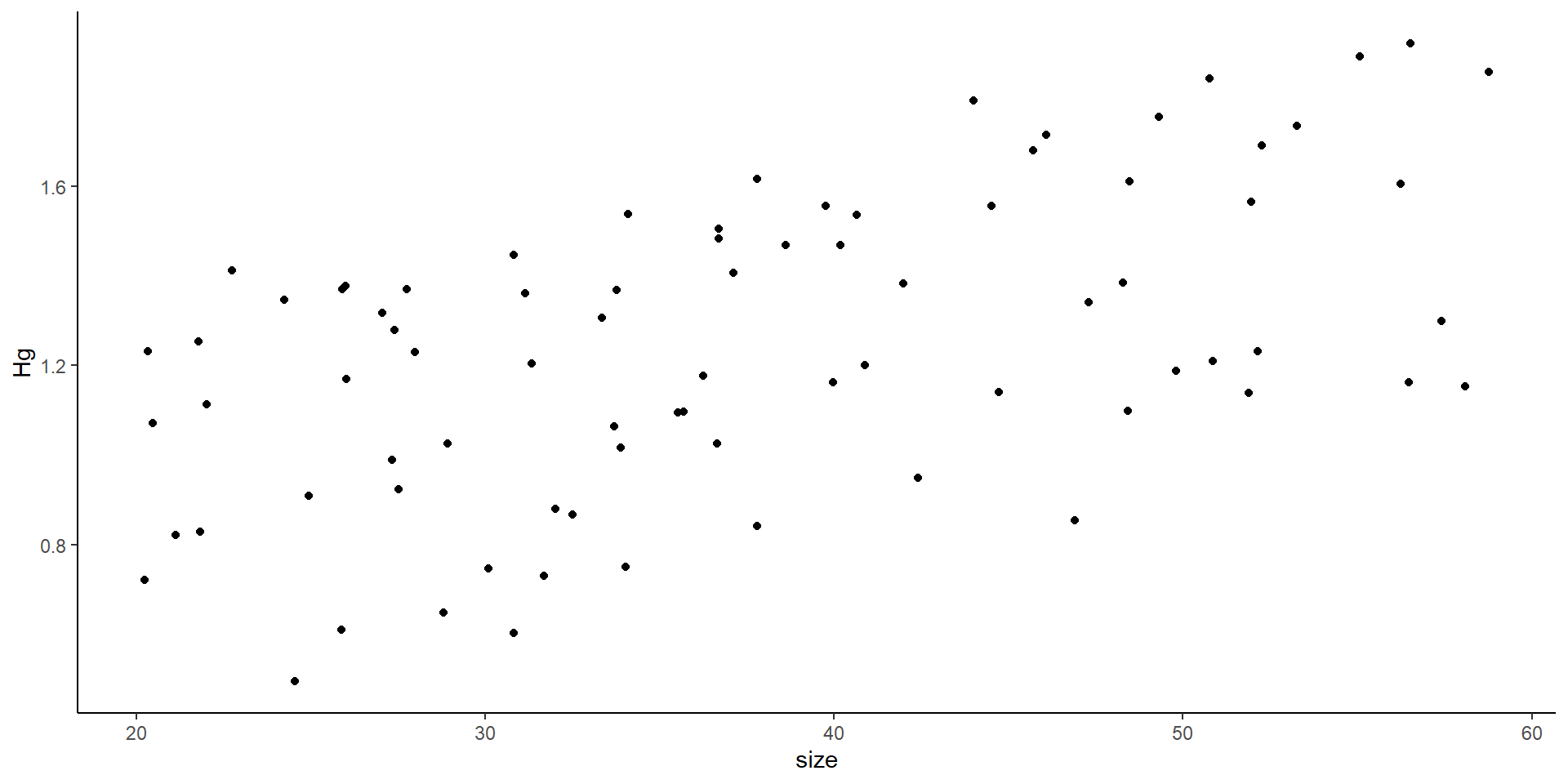
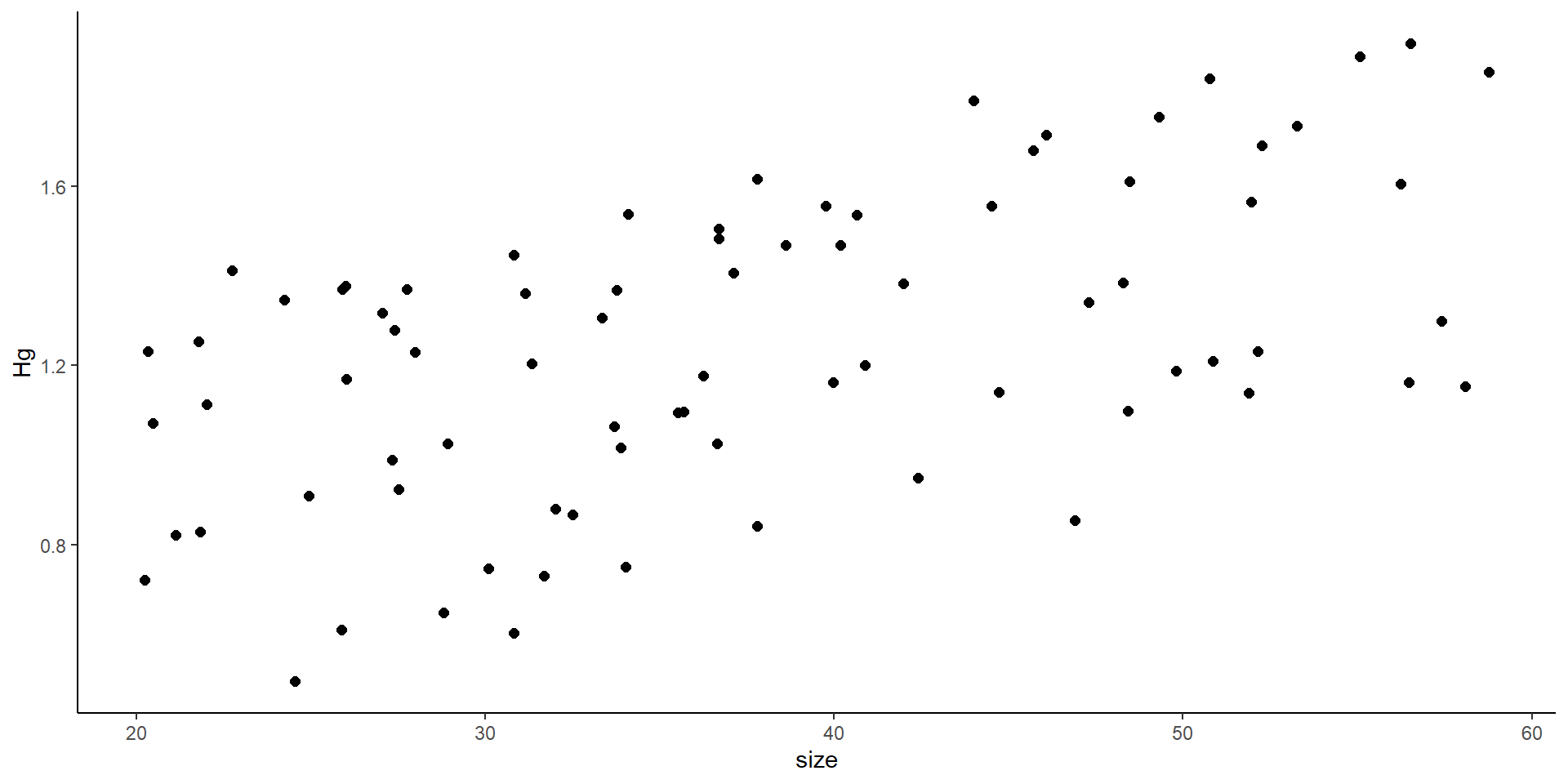
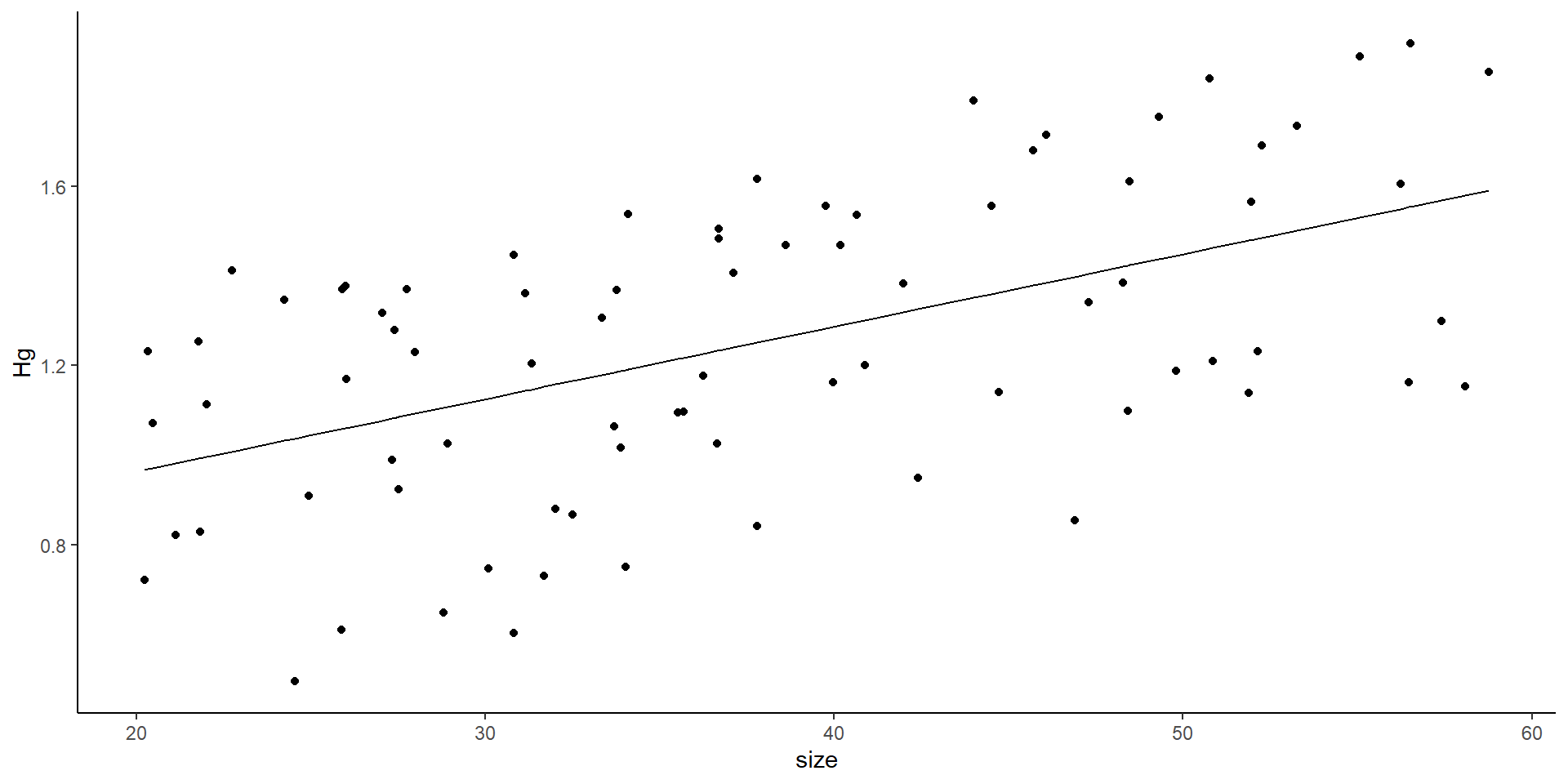
Fish and Hg. Research question: Should we limit consumption of fish over a certain size
Infection prevalence in turkeys: Research question: You are estimating the probability of an individual being infected to be used as a section on a demographic model?
Mice. Research question:Is the drug affecting the mice heart rate?
People Research question: How does educational level affect unemployment time?
Experiments : 🎣 🦃 🐁🧑🏭
For one experiment answer:
How would you analyze the data
Are they breaking any assumptions???
What is the individual unit, and what is the experimental unit
What is the response variable
Where is the variance coming from?
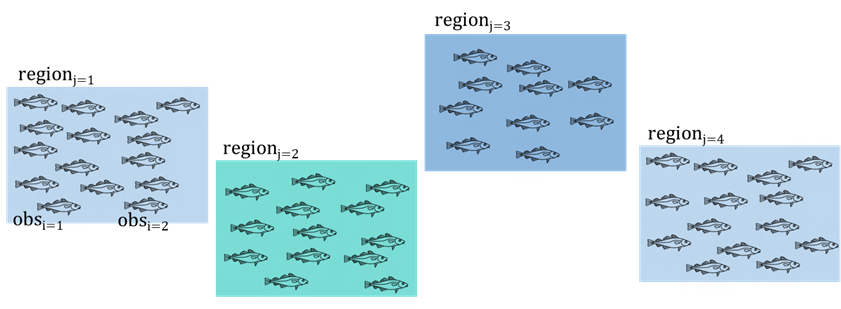
Example 1:
In the first example, we are looking at the relationship between size and Hg concentration, in order to know whether to publish a consumption advisory for fish over a certain size. So, far, we have looked at examples in which our sampling is “random”
size Hg region ind
1 41.99086 1.3827550 A 1
2 33.89565 1.0172009 A 2
3 51.96077 1.5652670 A 3
25 40.18645 1.4688691 B 25
26 37.12595 1.4055383 B 26
27 20.46721 1.0708612 B 27
56 49.80884 1.1882948 C 56
57 42.40157 0.9499704 C 57
80 56.51251 1.9176455 D 80
NA NA NA <NA> NA