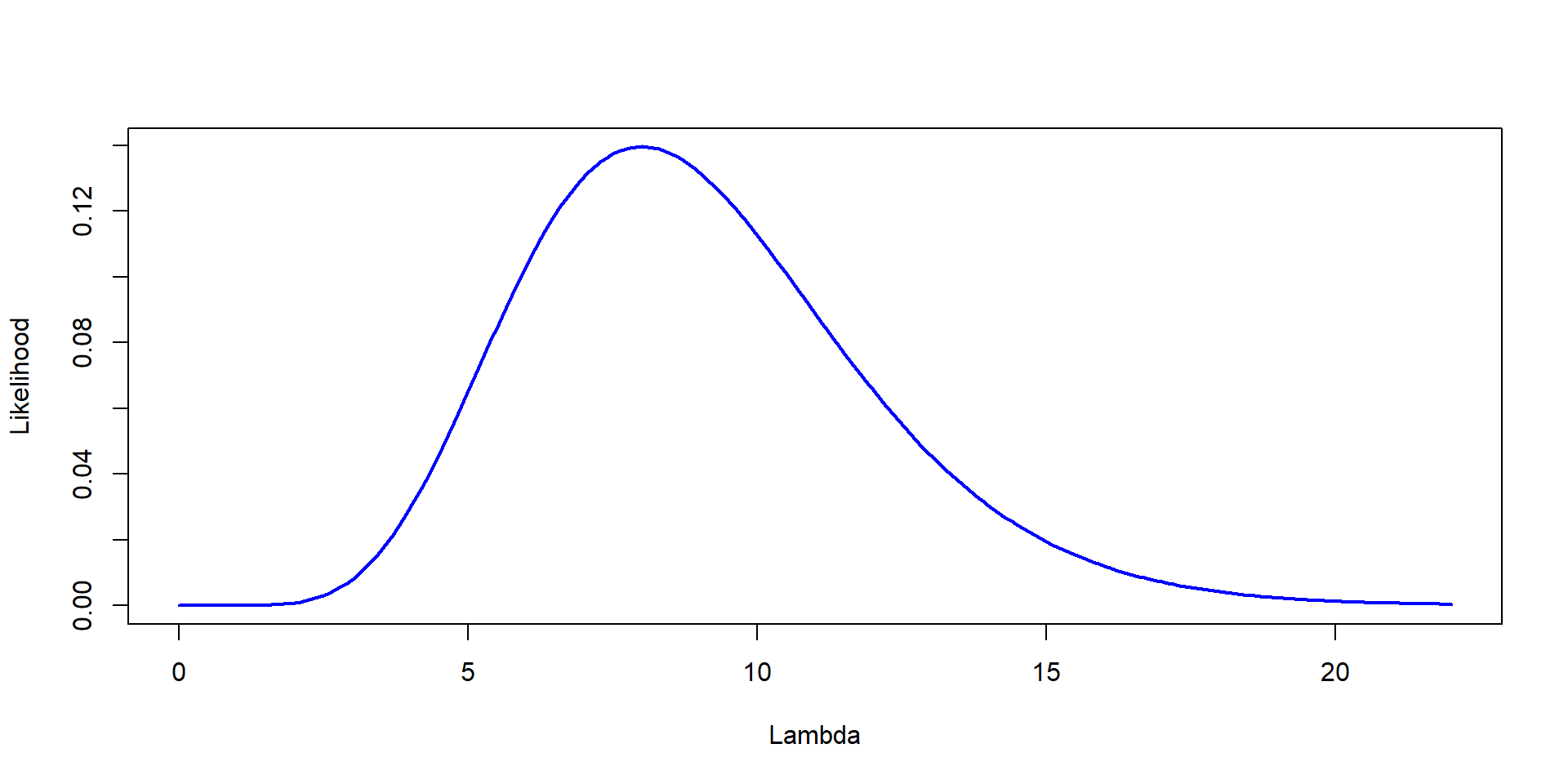
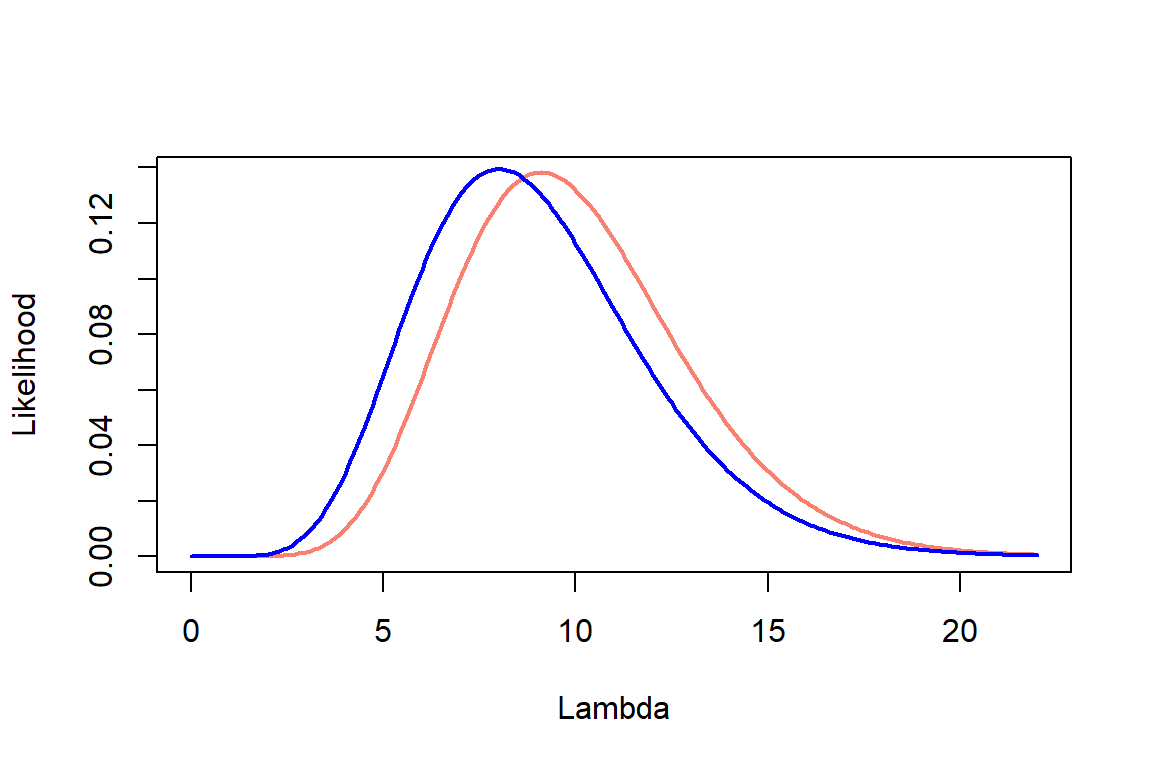
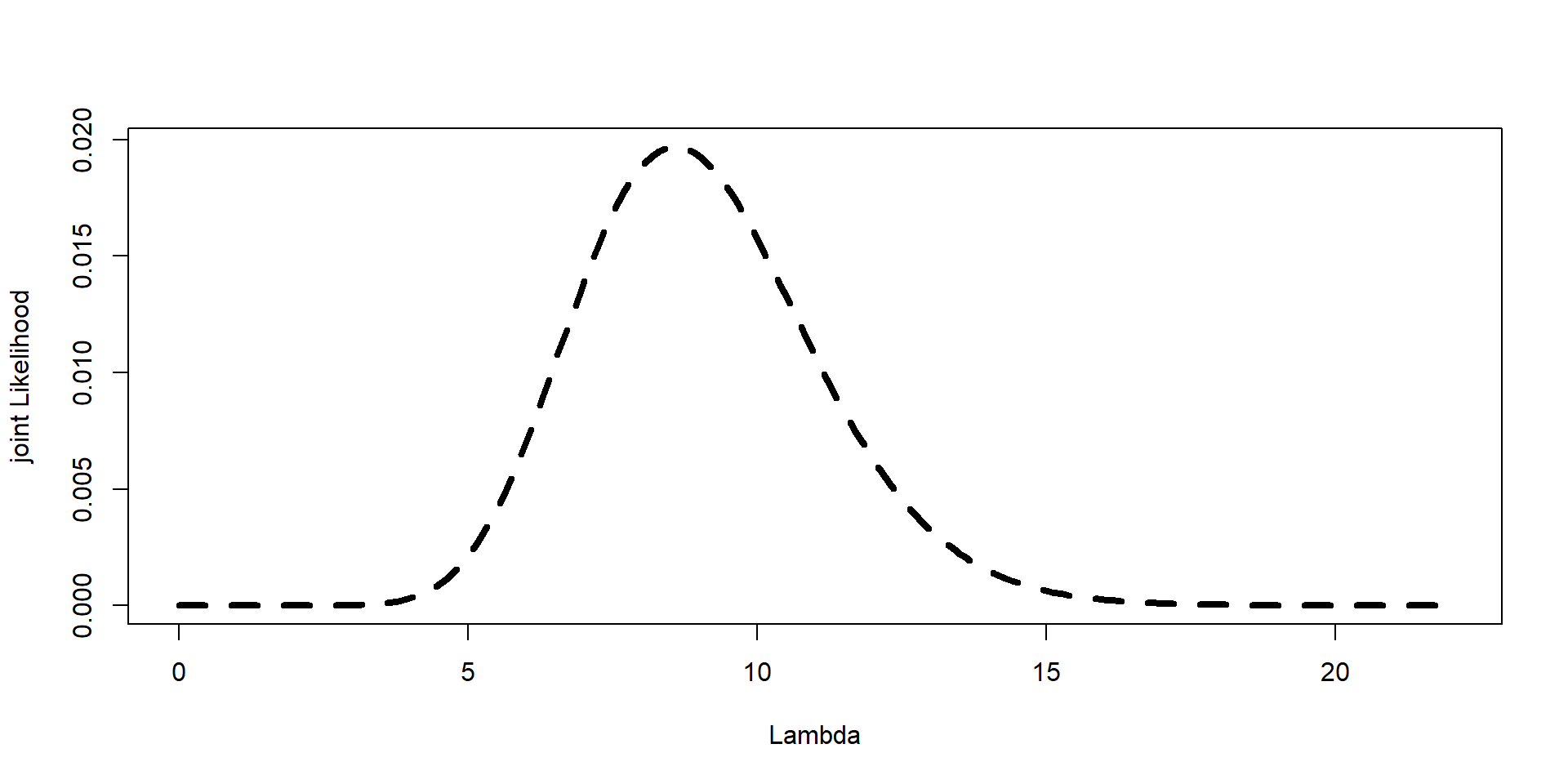
In frequentist: Equations that minimize residuals. It uses calculus and algebra
You get the same solution each time. If all of you run the same model with the same data in R, you will all get the same betas as me!
Bayesian Integrates a posterior –> No closed solution!
Different solution each time!
Why? Bayesian cannot solve this using an equation. So, it samples from it using Markov Chain Monte Carlo (MCMC!) and obtains a probability from it
MCMC?
Ever heard of this?
Let’s try this! With a game!
In-Pairs Exercise: Acting Out an MCMC Random Walk
Goal
Experience how MCMC explores a likelihood surface step-by-step. NO COMPUTER NEEDED!
DO NOT RUN ANYTHING YET!
Choose one student to do the random walk, one to be the computer or tester
Exercise
Goal
Experience how MCMC explores a likelihood surface step-by-step. NO COMPUTER NEEDED!
Setup
Student A: open and run the following code (DO NOT SHOW TO STUDENT B!):
x <-seq(-50, 150, by =1)# Create a landscape with 3 peaks of different widths and heightslikelihood <-0.7*dnorm(x, mean =20, sd =10) +1.0*dnorm(x, mean =80, sd =15) +0.4*dnorm(x, mean =120, sd =5)# Normalize so it looks like a probability surfacelikelihood <- likelihood /max(likelihood)plot(x, likelihood, type ="l", lwd =3, col ="darkgreen",xlab ="Parameter value (x)",ylab ="Relative likelihood",main ="Example Likelihood Landscape")
Student B: secretly pick a starting point (between 0 and 100). Call this x
The Walk
Student B: Write down the starting point (x) and mention it to student A. Student A tell student B an approximate value of the Likelihood. Write it down.
Student B: flips a “coin” in R:
rbinom(1, 1, 0.5)
[1] 0
If 1 –> propose x + 3
If 0 –> propose x – 3
Student A: checks the new height (likelihood) and compares it to the current. If new height > current, move 3 steps in that direction (Student B: write down the new x, student A write Likelihood) If not, move only 1 step. Write down the new x and Likelihood as well.
Repeat ~20 times
Plot in paper (x value vs Likelihood)
MCMC
Start with a random guess.
Propose a new set of parameters.
Accept or reject based on how likely they are given the data.
Repeat thousands of times. The chain “learns” the posterior shape.
Youtube video
Gibbs sampler
Most of our software uses a Gibbs sampler.
It tests one parameter at a time.
Fixes some parameters and moves one around
After a while, it switches to a different parameter, and so on
Next classes (suggestion)
Wednesday: Plots
Friday: A Bayesian example (only for those interested).
Next Week: Multivariate (lecture). Friday lab, no need to turn in, but an exercise I want you to do
Monday 24: Session to work on final project (no class)
Monday 1st. Session to work on final project (no class). Free coffee + snacks (RSVP)!